LlamaIndex instrumentation
- Query Engines
- LLMs
- Agents
Thread, Run and Generation logs,
and show you a visual of what you can expect on Literal AI.
Query Engines
Thread will result in the following tree on Literal AI :
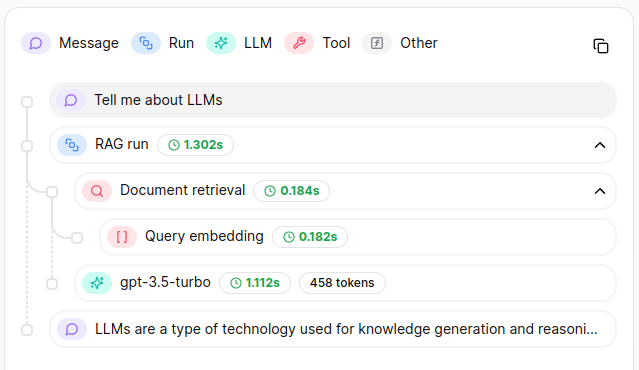
A LlamaIndex RAG thread on Literal AI
LLMs
LlamaIndex offers wrappers around LLM providers to interact with their APIs.llm.chat
The methods llm.chat and llm.stream_chat both generate a standalone Generation:
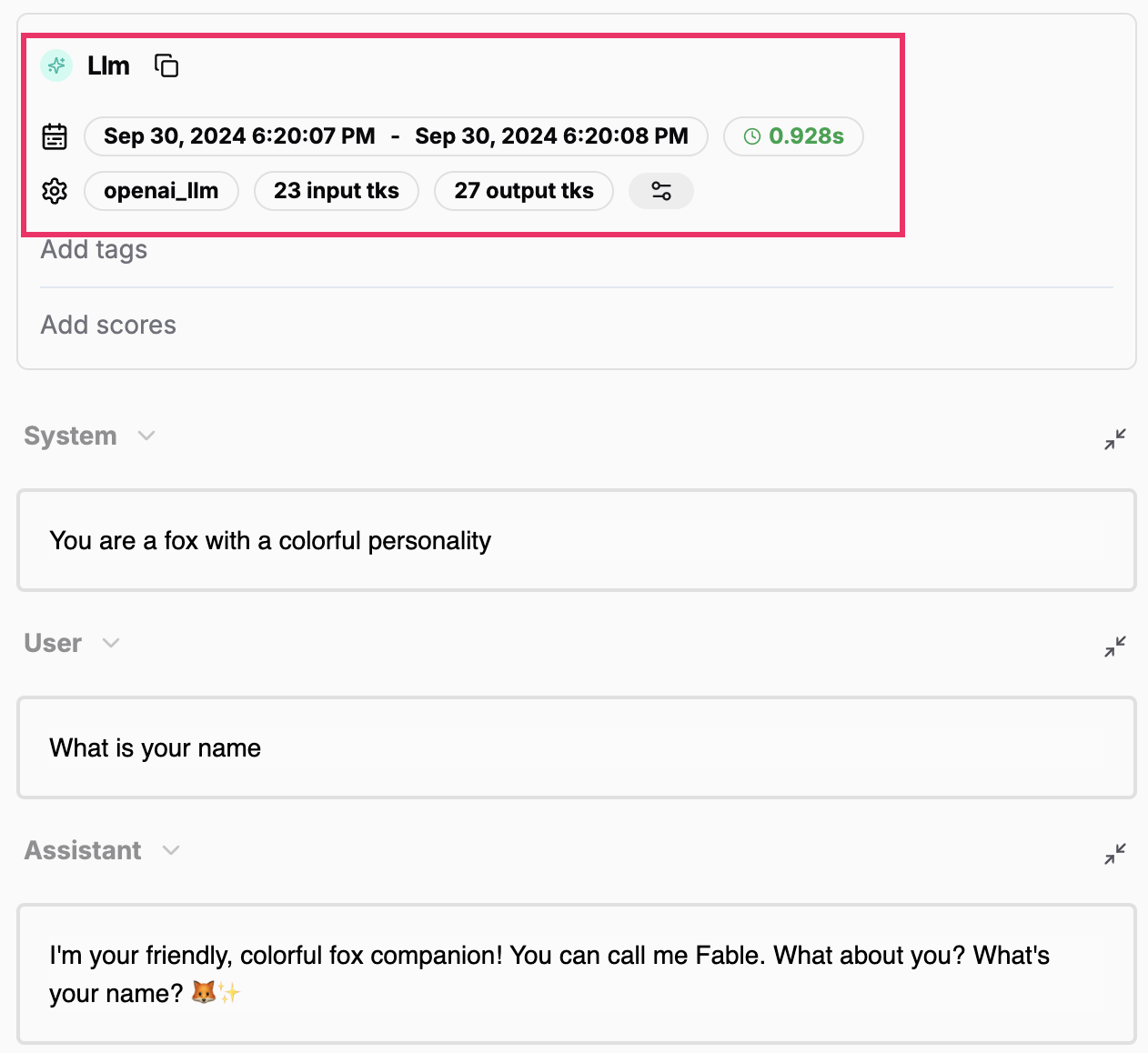
A LlamaIndex LLM call - Standalone Generation
Please note that LlamaIndex token usage is not available for streaming methods due to limitations
in the event data present on the
LLMChatEndEvent for chunk completions.However, the Literal AI platform defaults token counts computation to the cl100k_base tokenizer
which is a fair approximation of the expected token usage.llm.predict_and_call
The llm.predict_and_call also results in a standalone Generation on the Literal AI platform.
Specifically, LlamaIndex does not trigger events related to tool calls and we recommend decorating
your tools’ function definitions with @literalai_client.step(type="tool", name="My Tool") to view
the calls performed.
Note that a Step of type tool cannot be standalone on the Literal AI platform and we thus
recommend you to add a contextual Step wrapper around your llm.predict_and_call call, as such:
LlamaIndex llm.predict_and_call
Agents
LlamaIndex has the concept of agent as part of itsFunctionCallingAgent and specifically derived
an OpenAIAgent with specificities to the OpenAI model offerings.
Function calling agents can be tuned in a variety of ways, but the general idea is that they iteratively
perform the configured LLM calls with tool options until the LLM deems it unnecessary to call a tool.
When calling an agent.chat, you can expect to obtain a “run” Step of the following form:
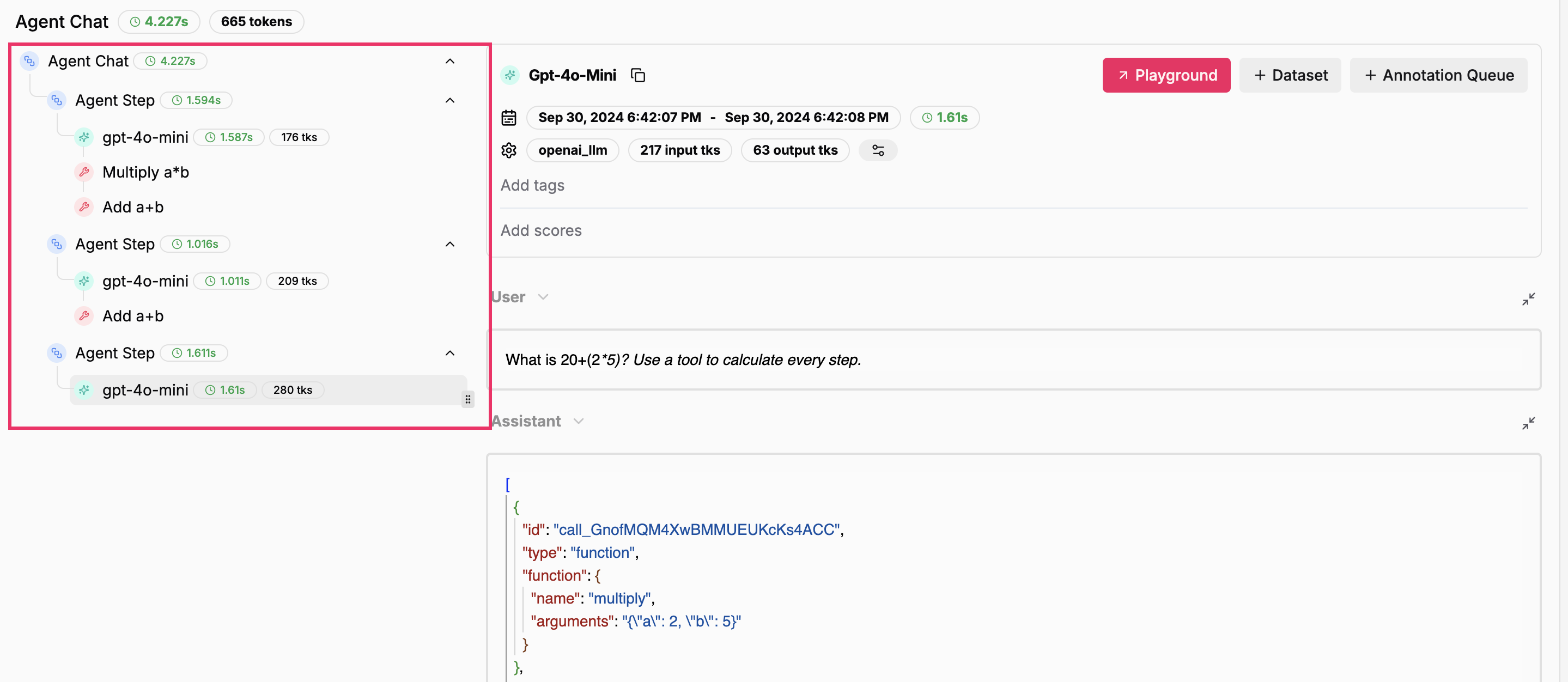
A LlamaIndex agent chat - Agent Run with multiple intermediate steps
@literalai_client.step(type="tool", name="My Tool").