How it works
Fine-tuning
LLM providers offer fine-tuning as a service, you simply need to provide the trainign data in the right format. Behind the scenes, the LLM provider freezes the original model’s weights and slides in a few layers of trainable weights (LoRA). Training happens on the LLM provider’s infrastructure and the loss function (cross-entropy) is the metric optimized against. Best practices are to pass in a training and a validation dataset to ensure your fine-tuned model is not overfitting.Dataset export
Literal AI simplifies the creation of training datasets withGeneration datasets.
You can build Generation datasets from your logs, or from your annotation queues: the format is compatible with the OpenAI fine-tuning format.
To download your datasets as JSONL (JSON Lines) files, you can use the Download button on the dataset page:
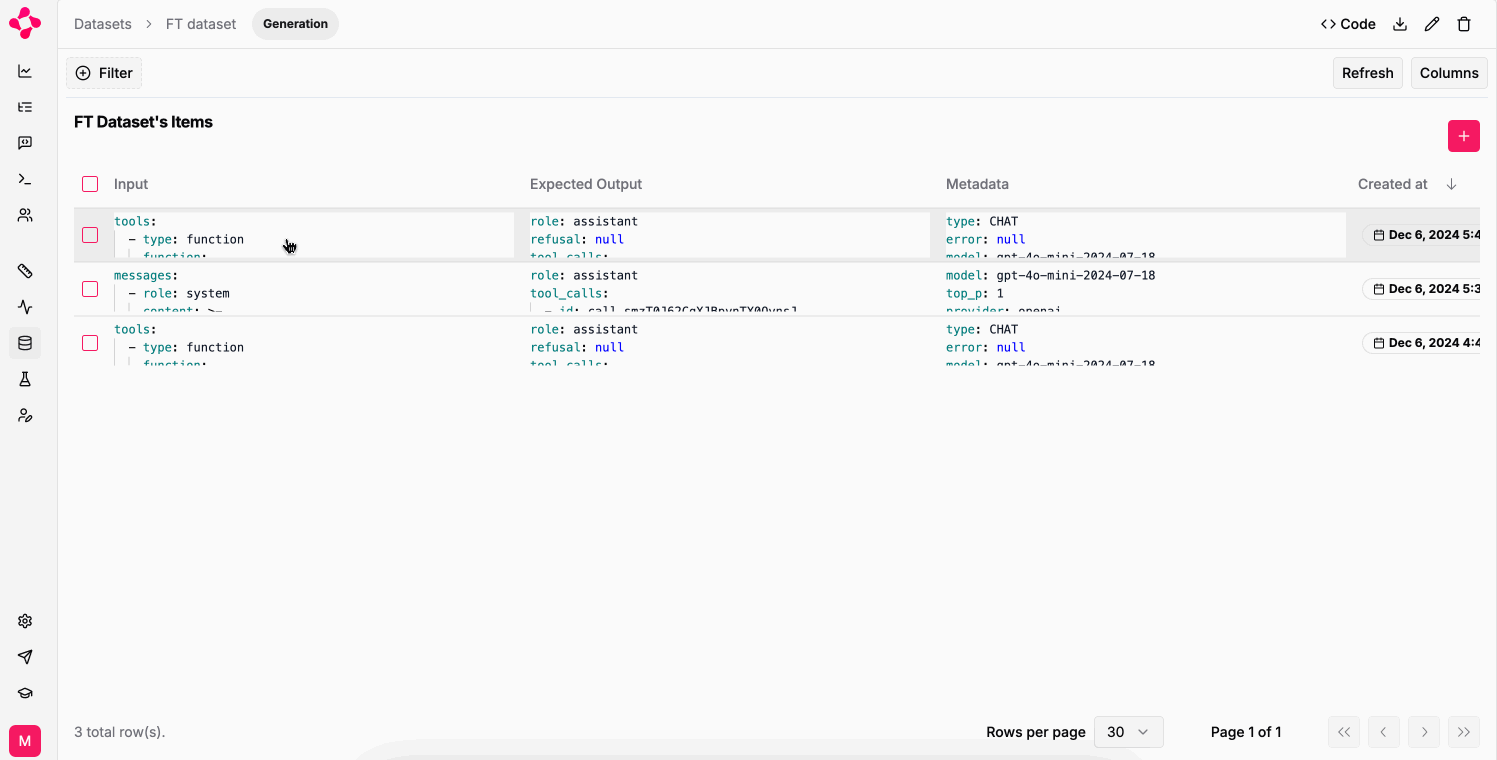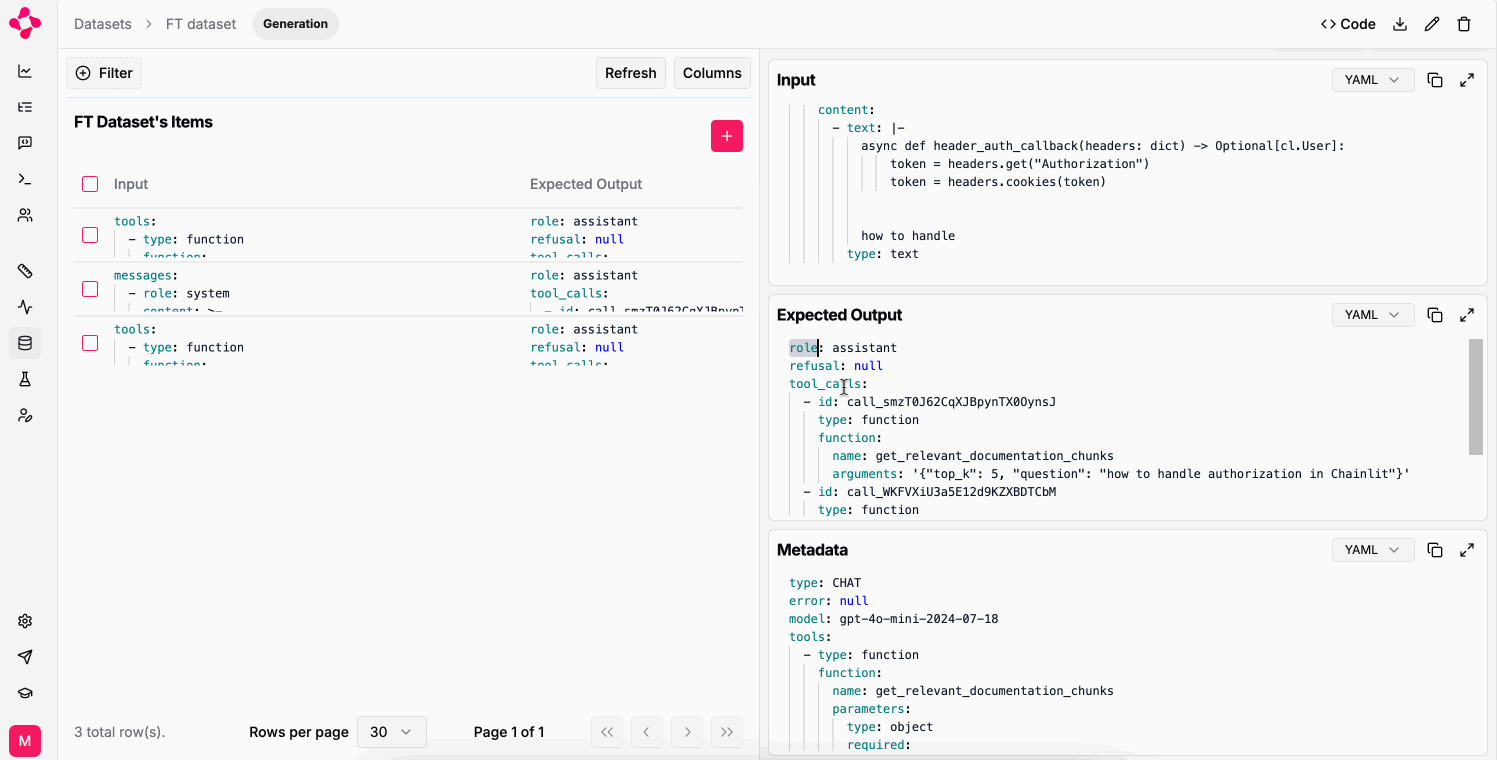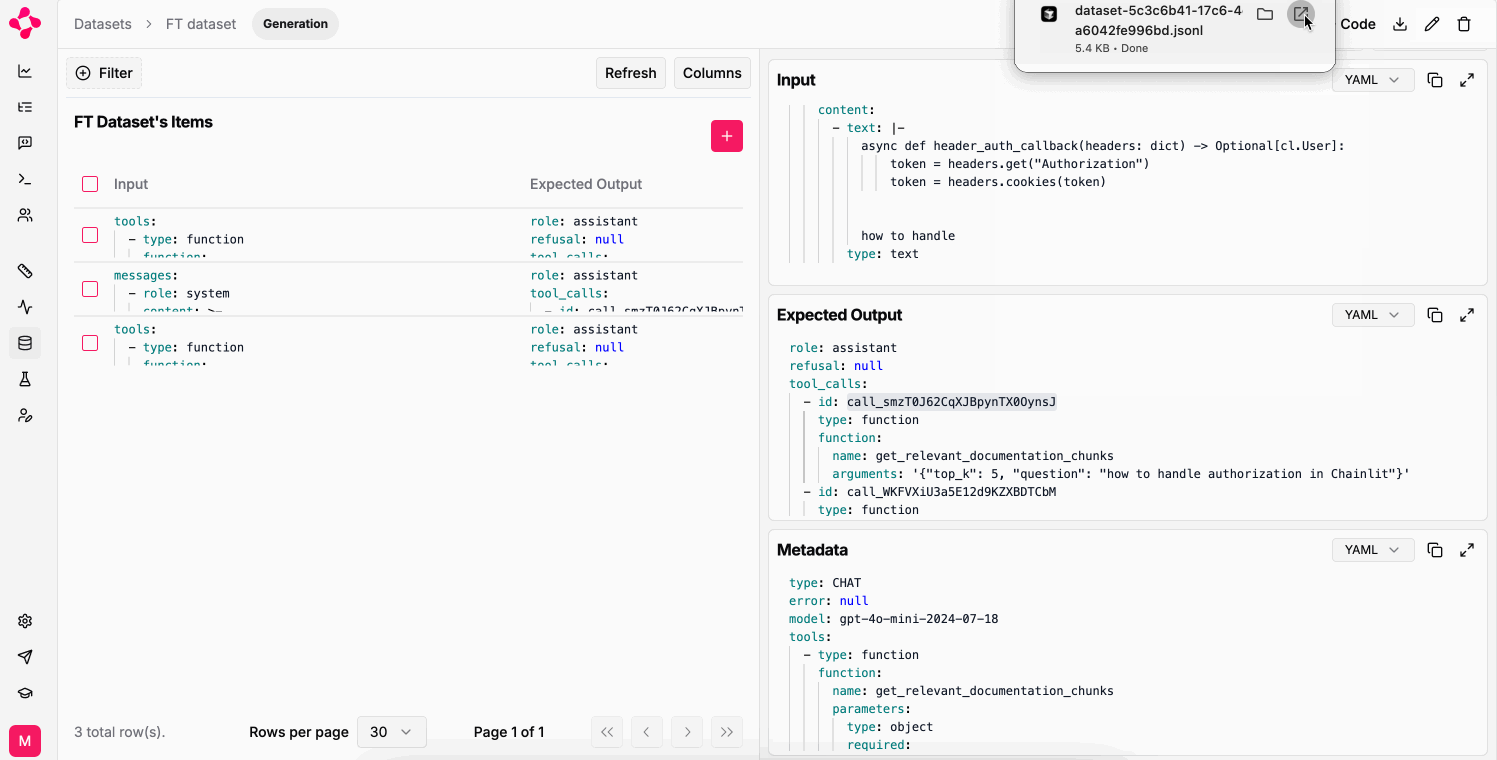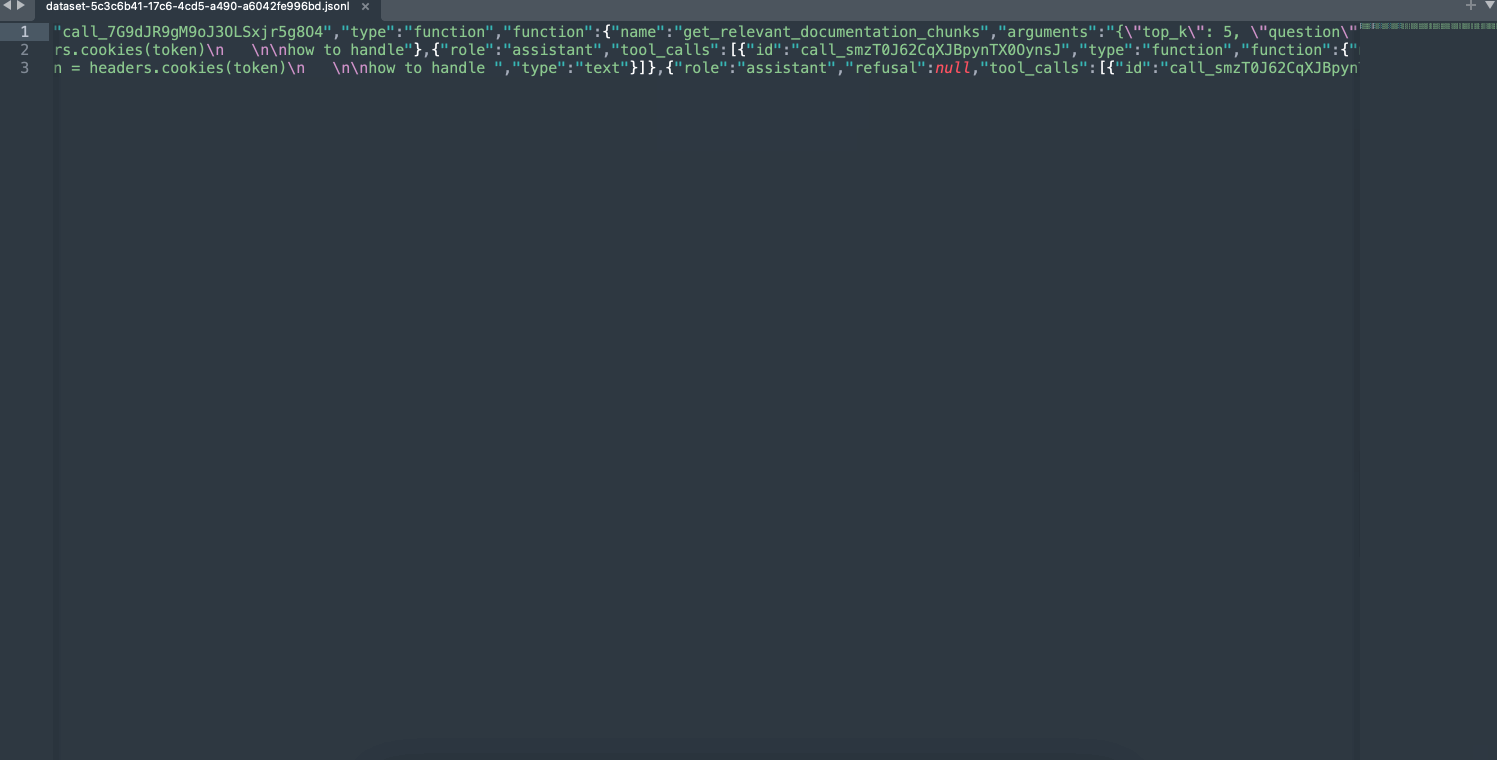
Download Generation Dataset
Distillation
Often-times, the hard part is to come up with the right dataset to train on. It should be:- high quality
- representative of the real-world task you want to use the model on
- large enough to train a good model