Run Experiments from Literal AI
Run anExperiment on a Prompt against a Dataset and a set of Scorers from Literal AI.
Experiments can be run directly from the Prompt Playground. This allows you to run experiments without having to manage an infrastructure.
Prompt to iterate on
Go to the Prompt Playground, make modifications to your prompt and vibe-check it.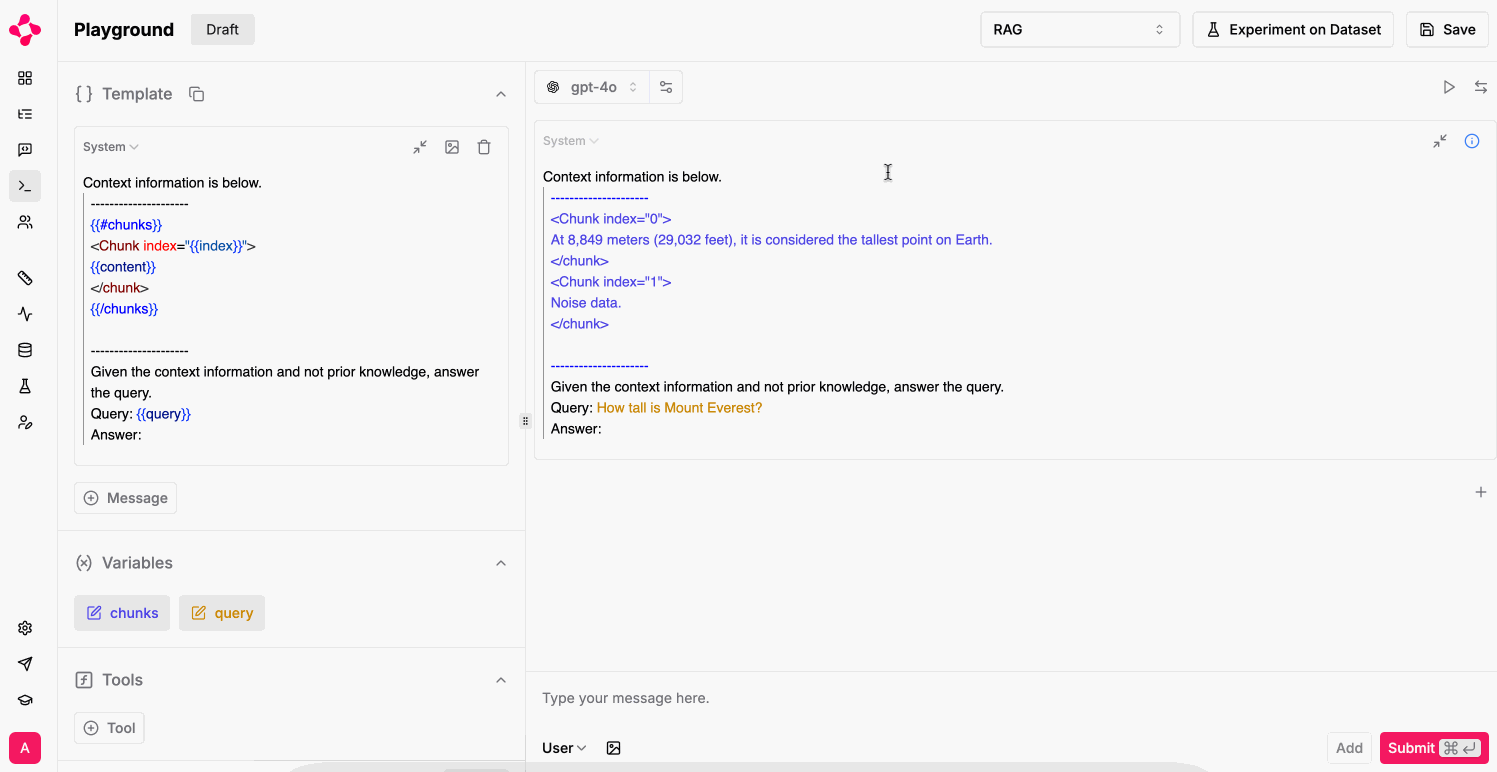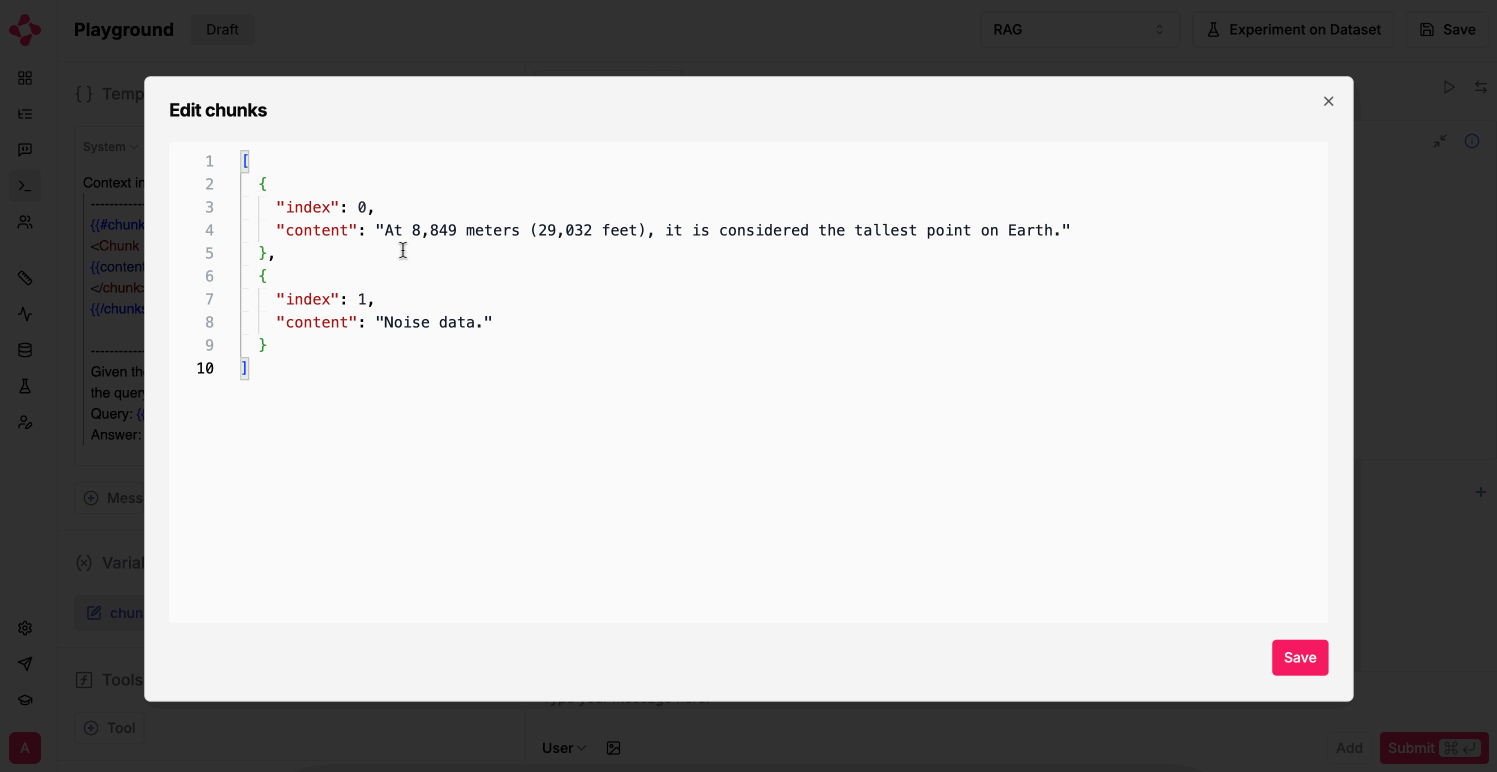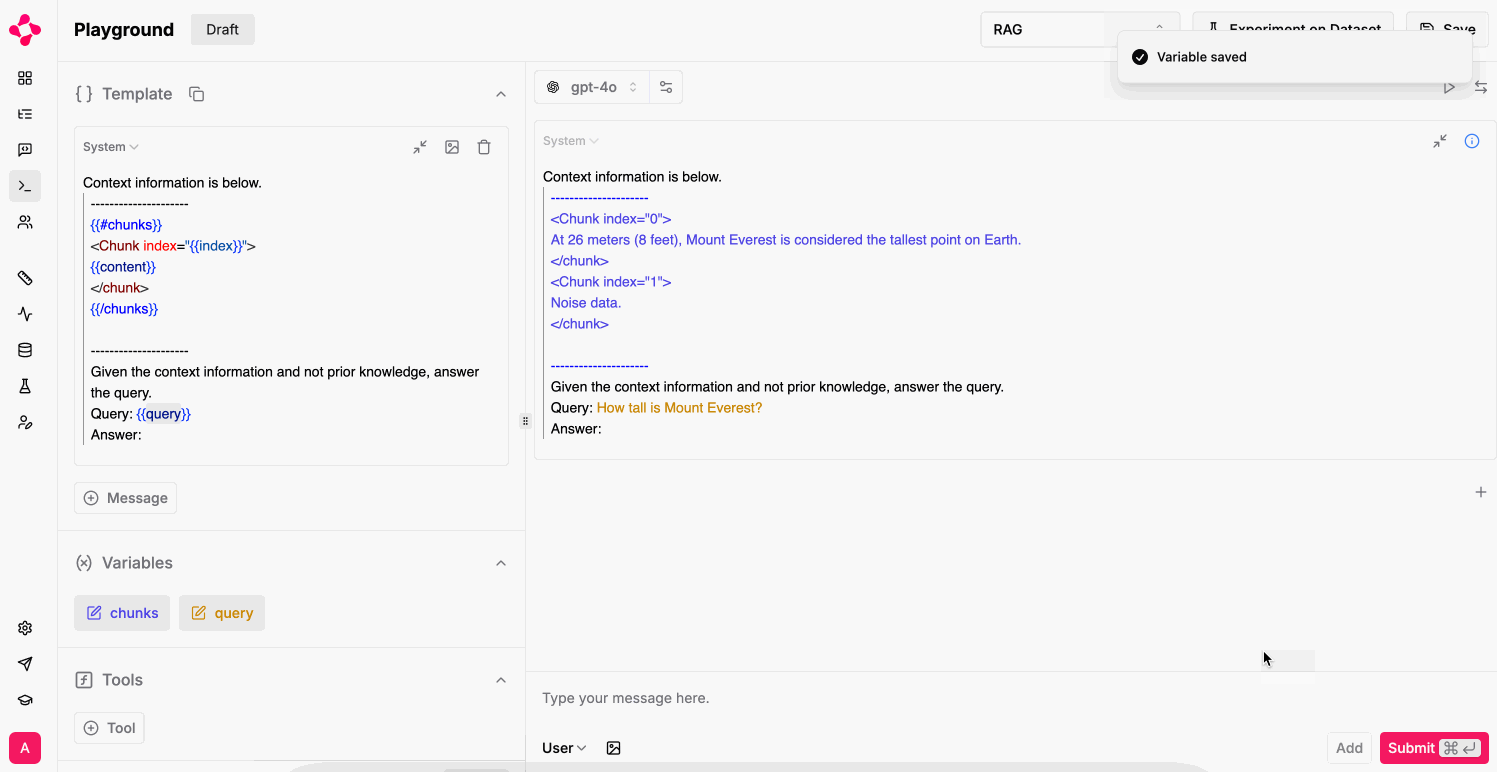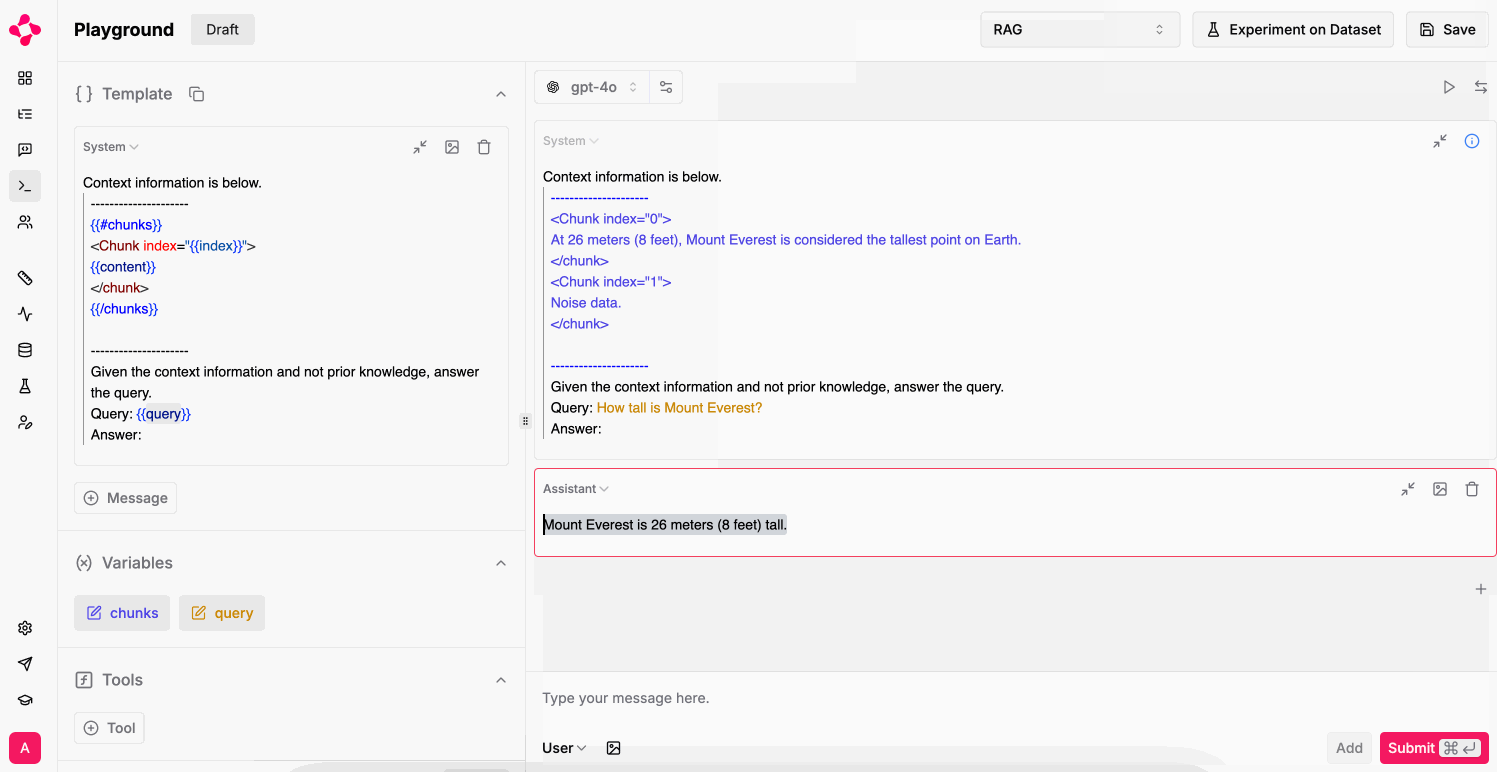
Pick a Dataset and select Scorers
In the upper right corner, click “Experiment on Dataset”.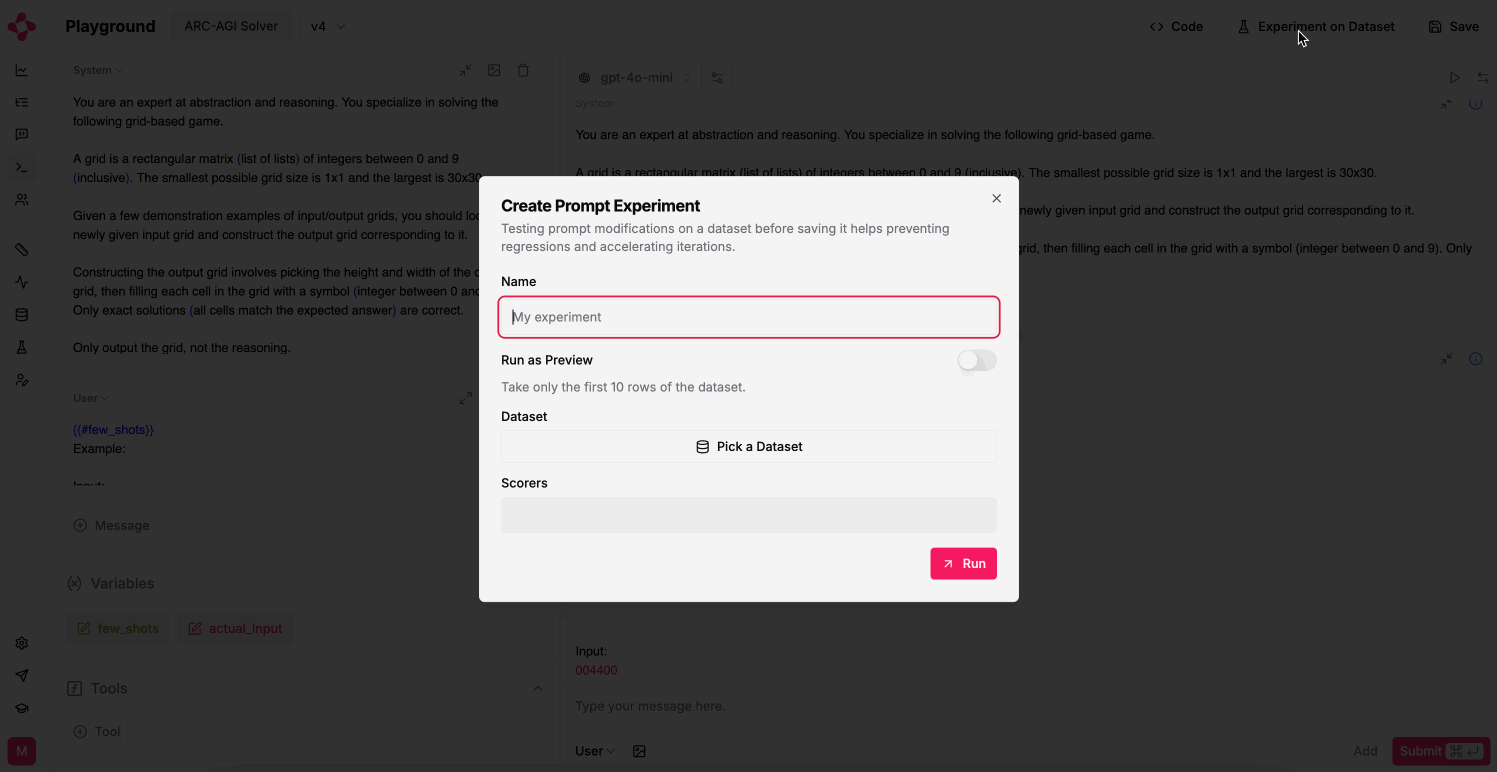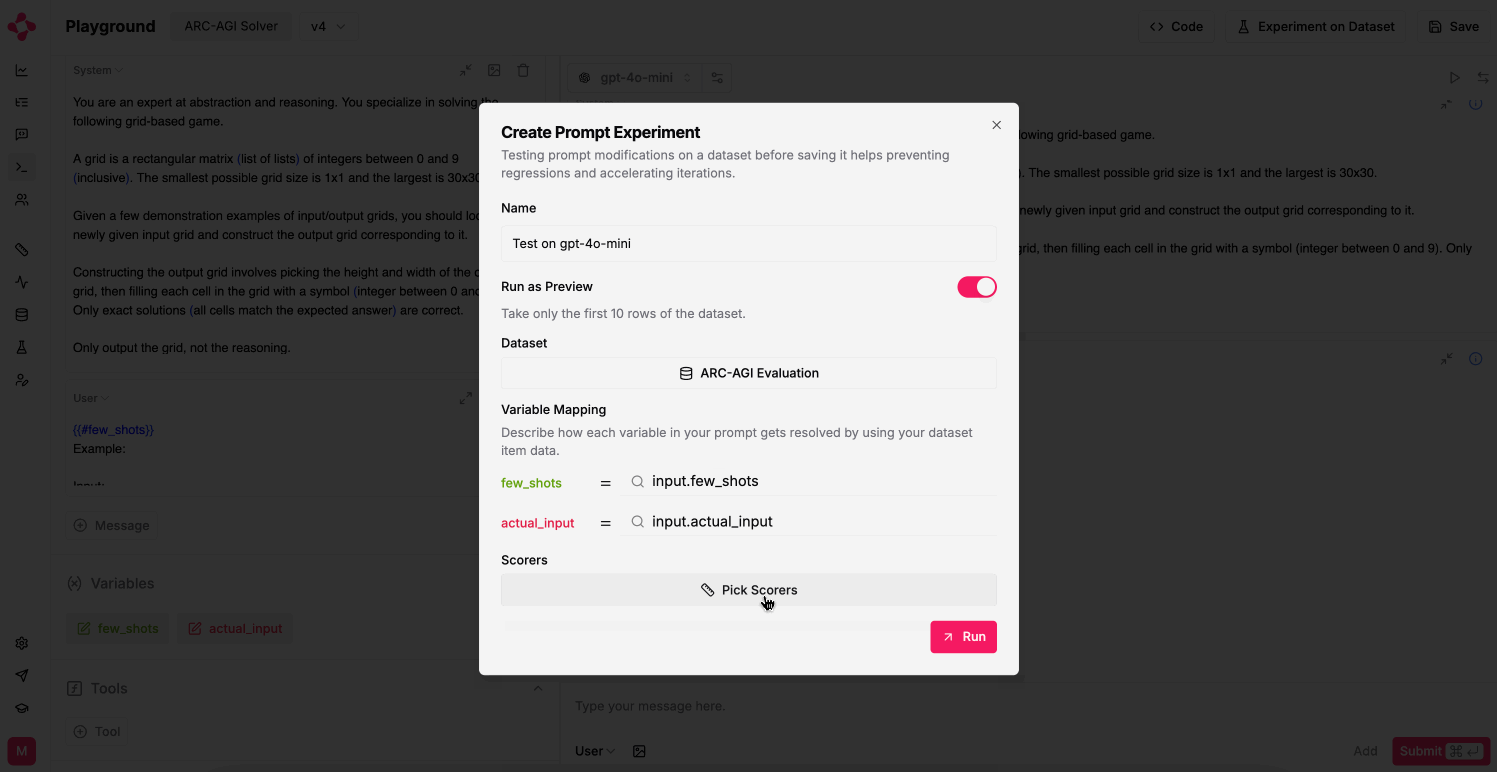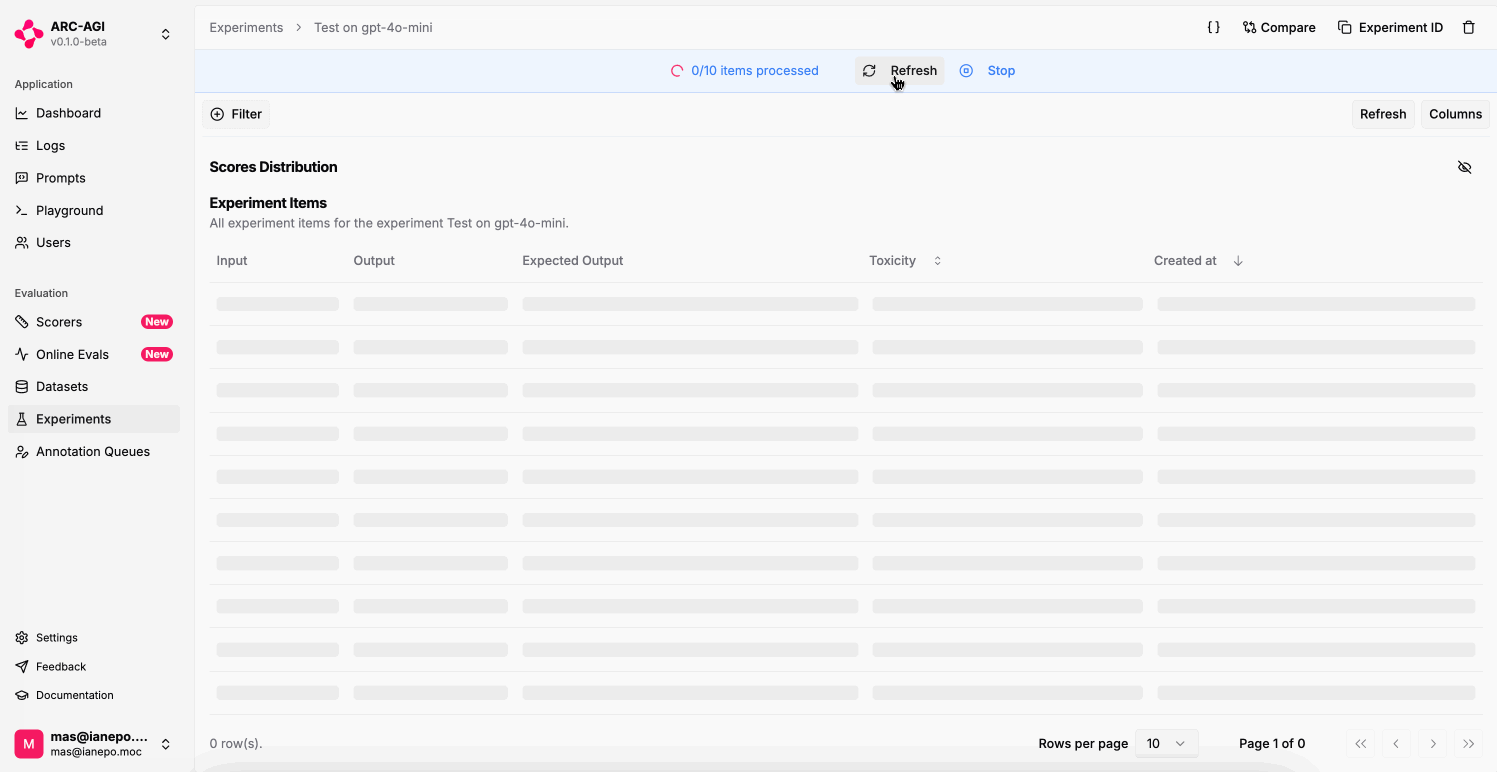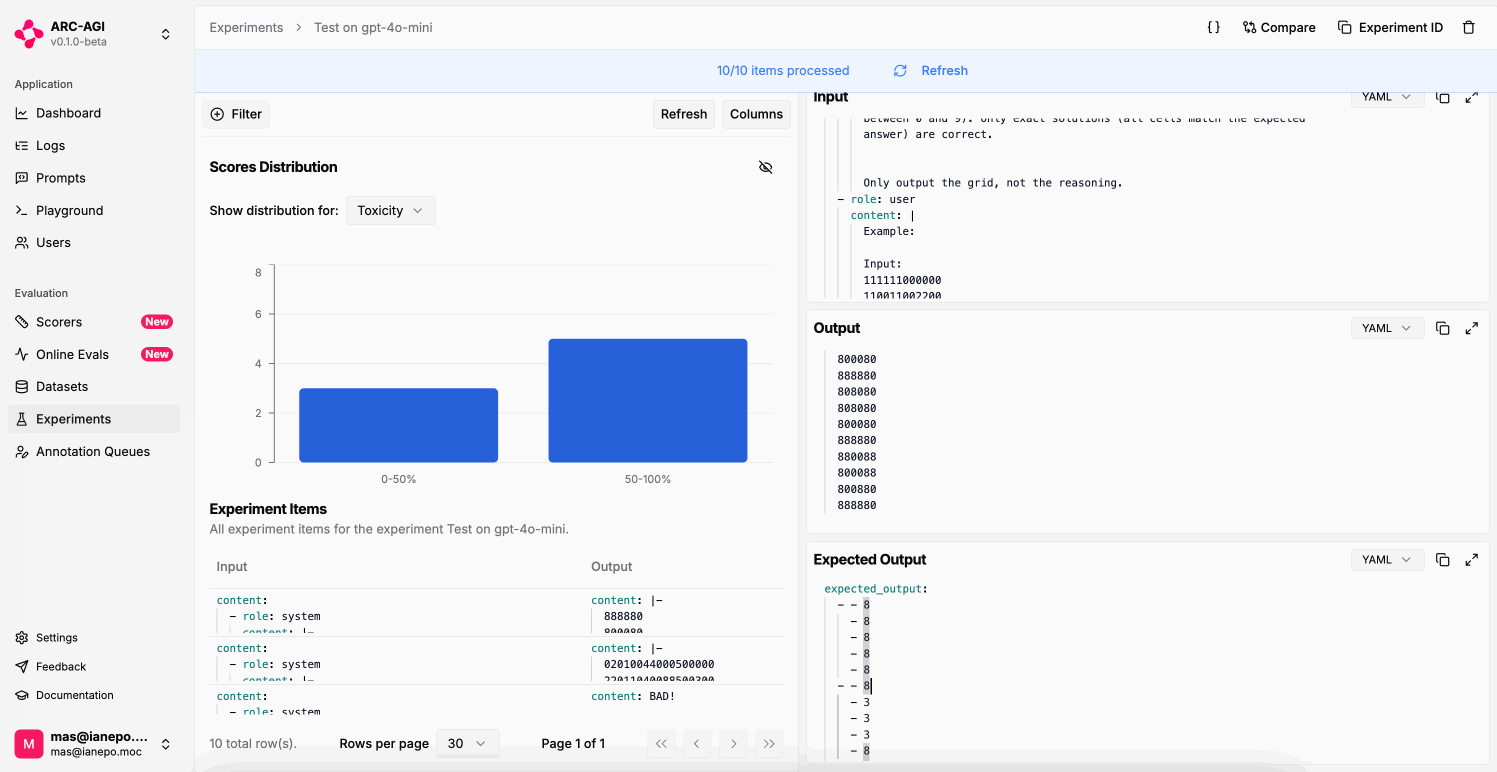
You should specify how to resolve prompt variables with your dataset
input, expectedOutput
and metadata columns. The Scorer configuration offers to
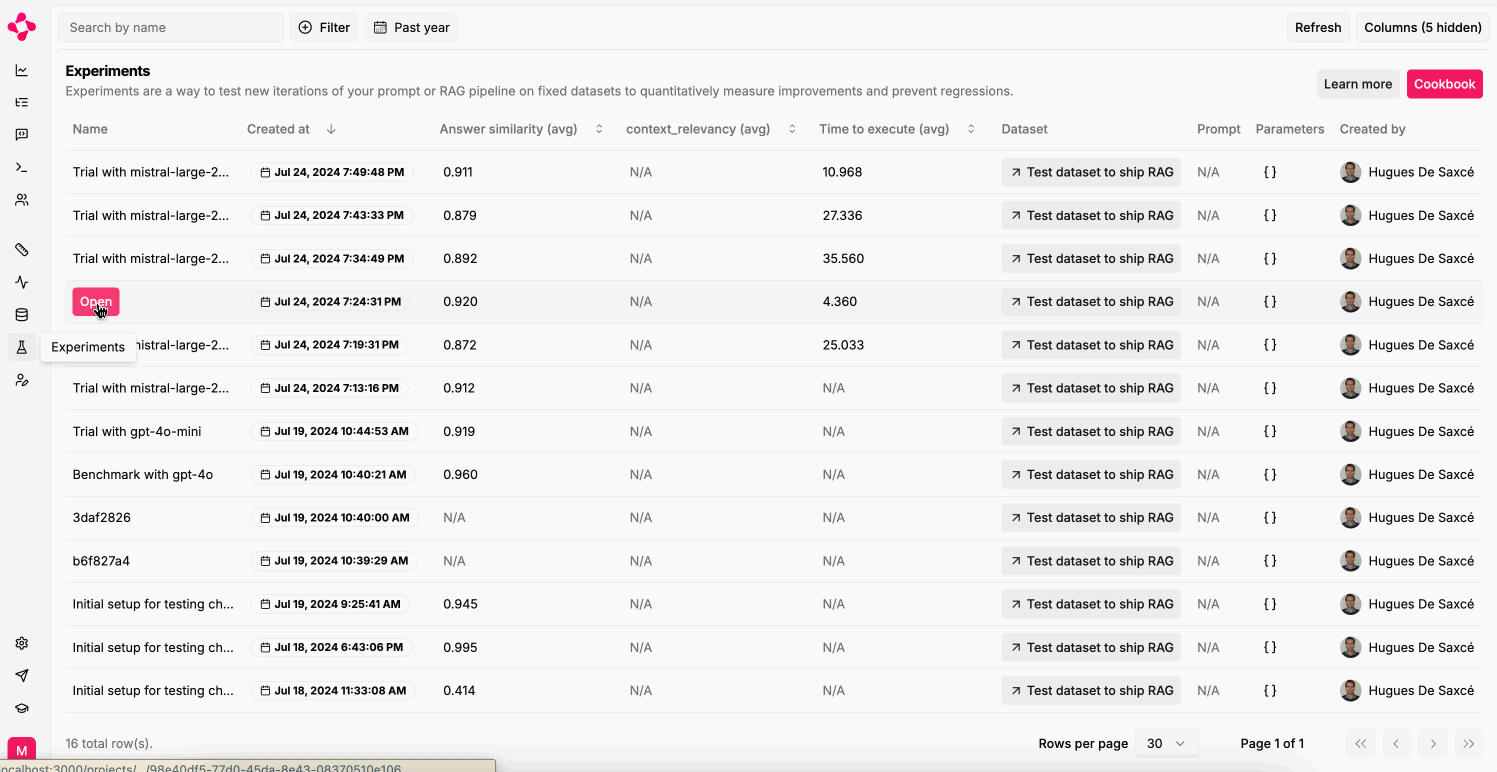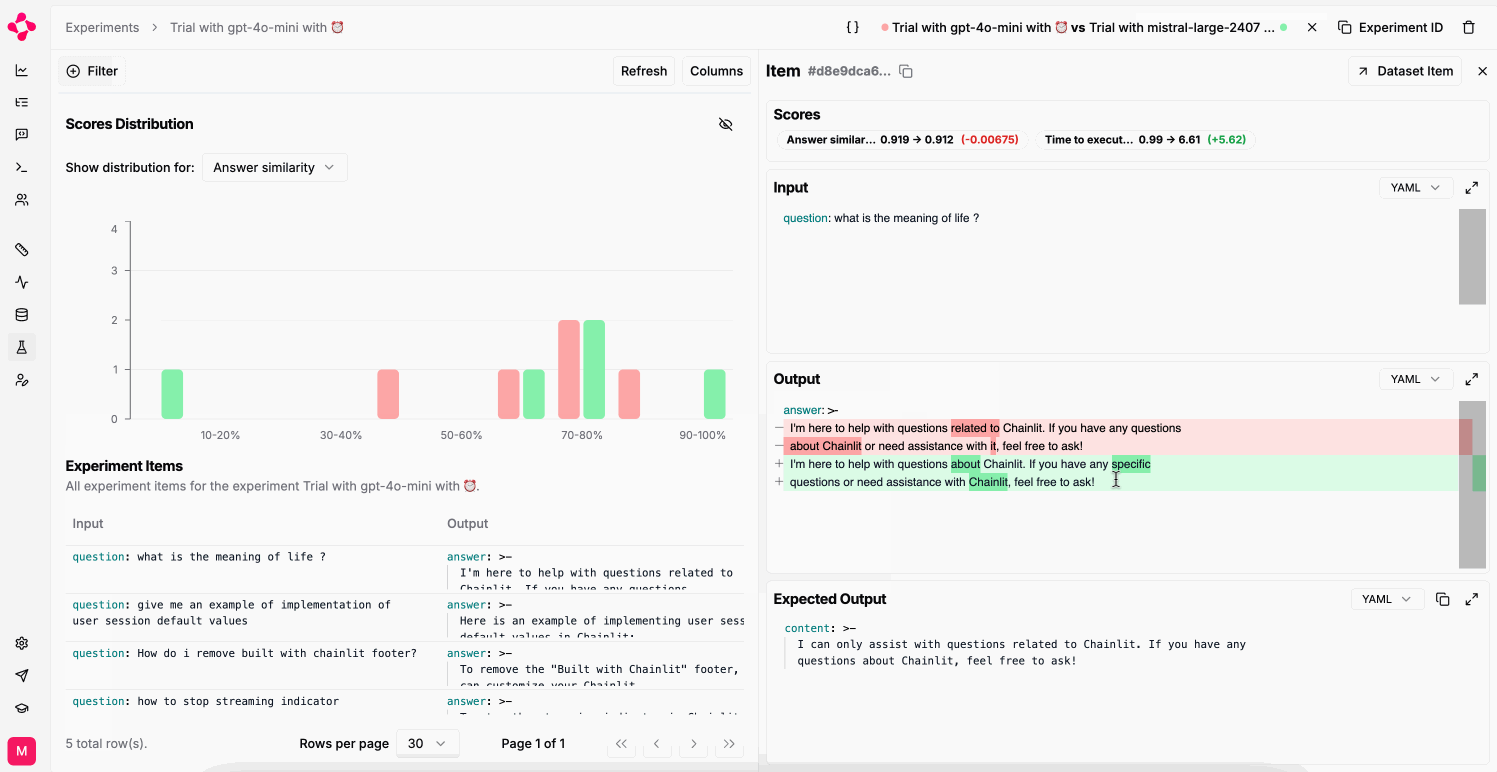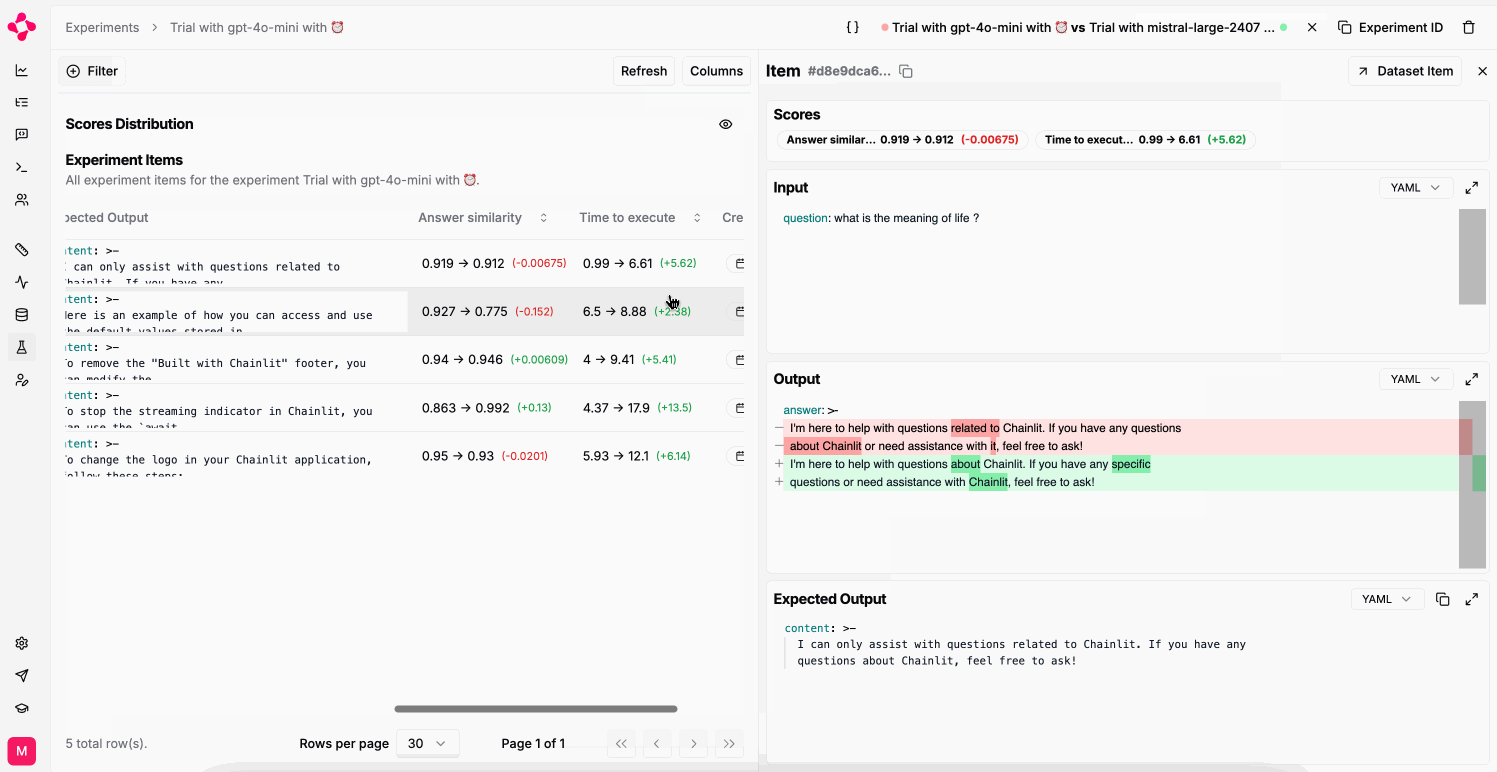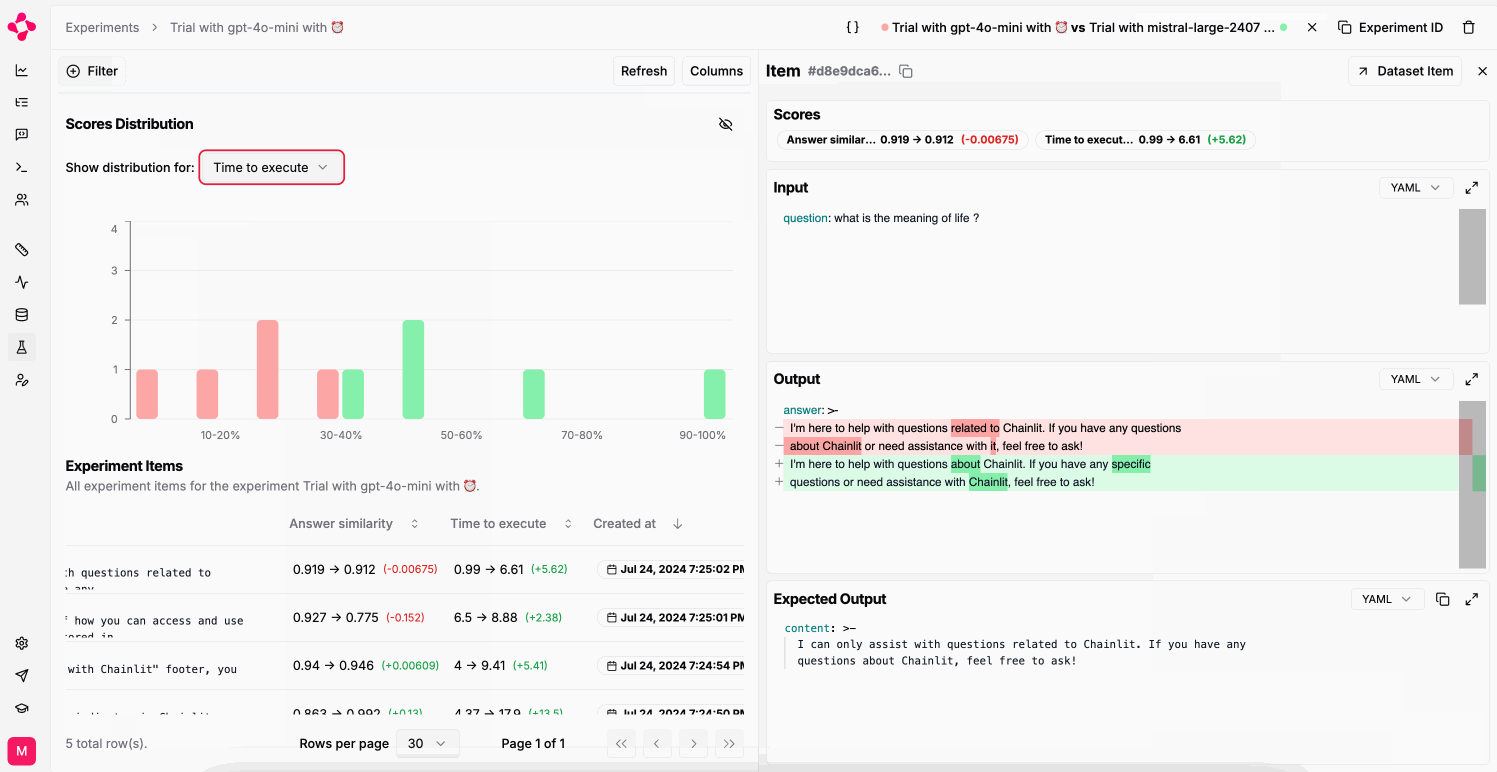
use the prompt’s completion through the output key.Compare experiments
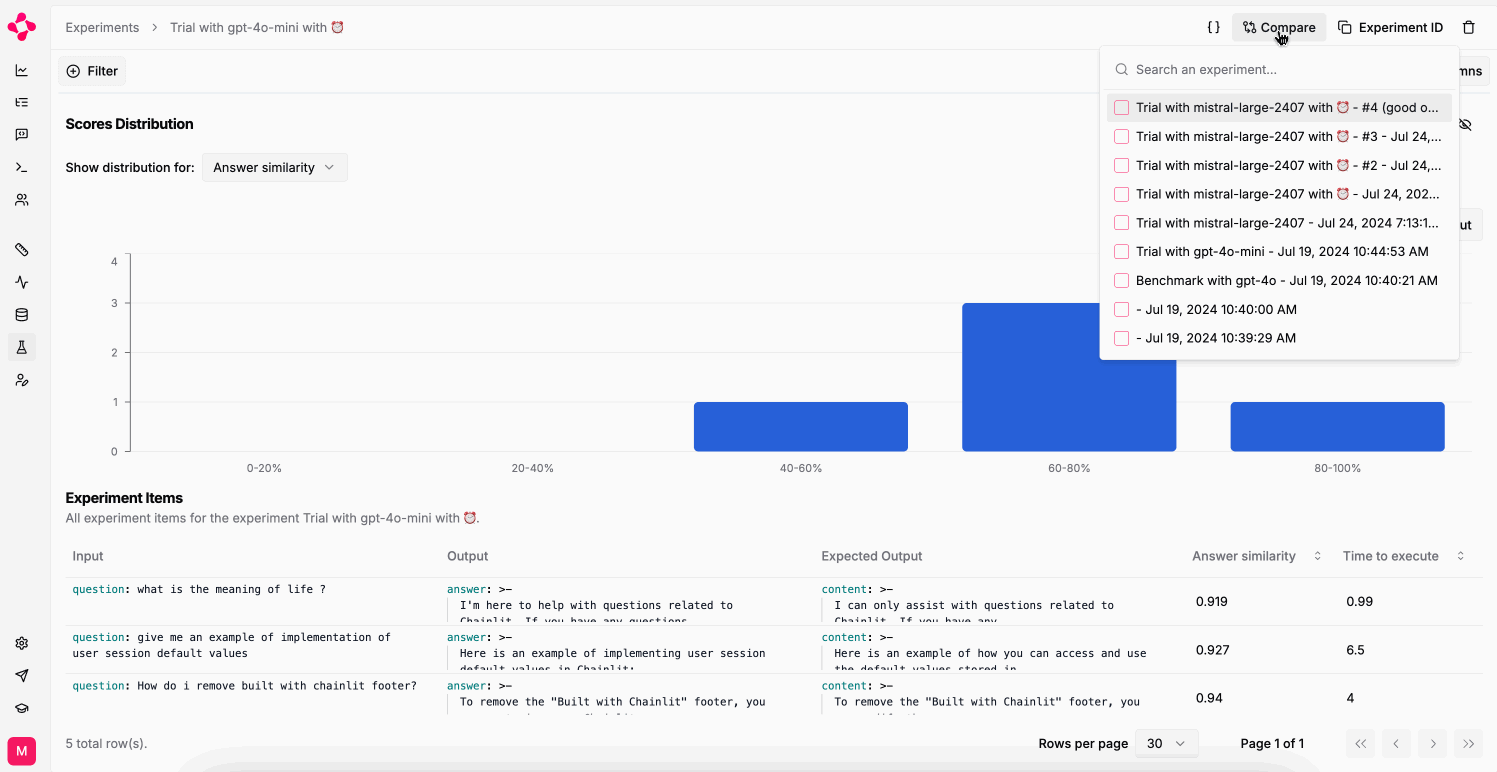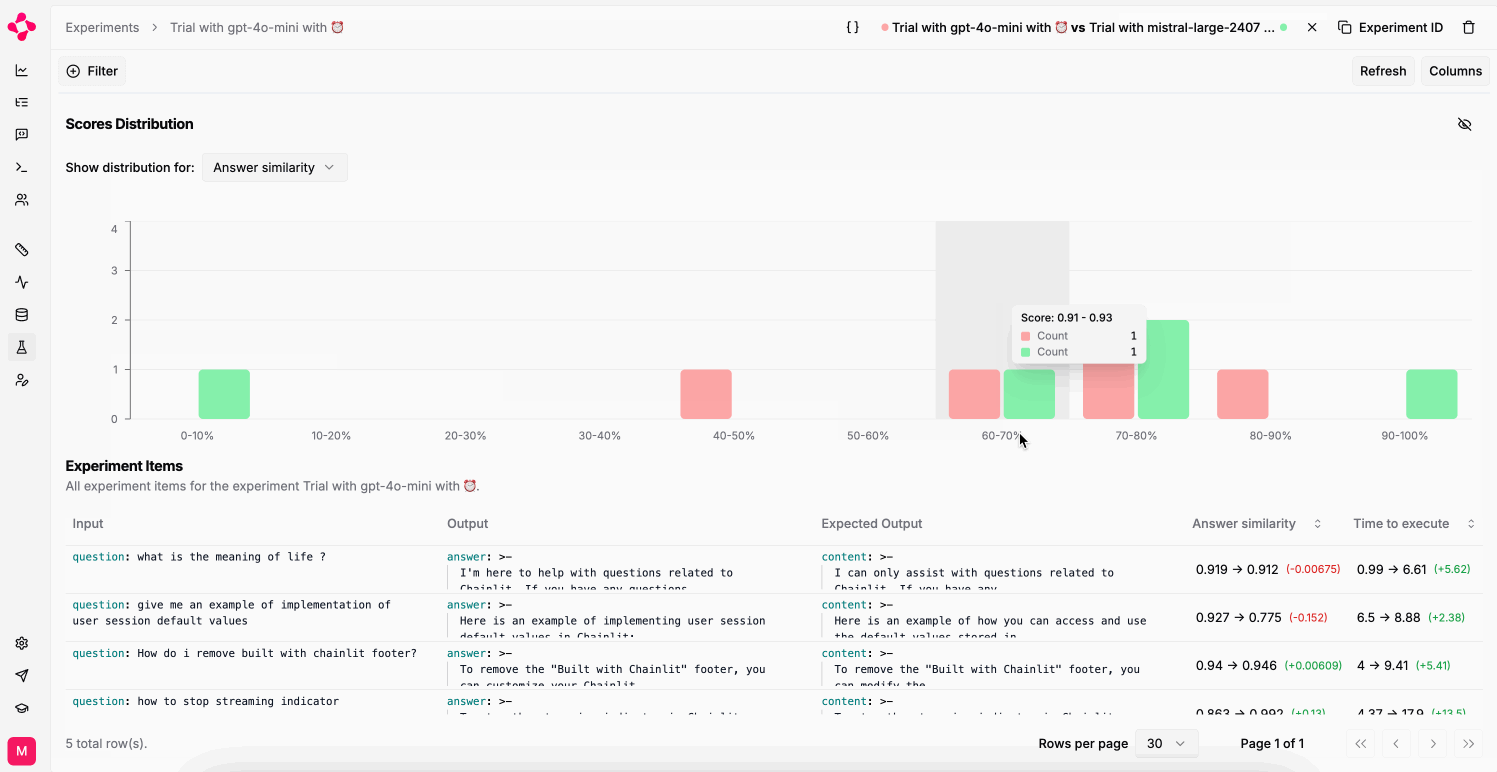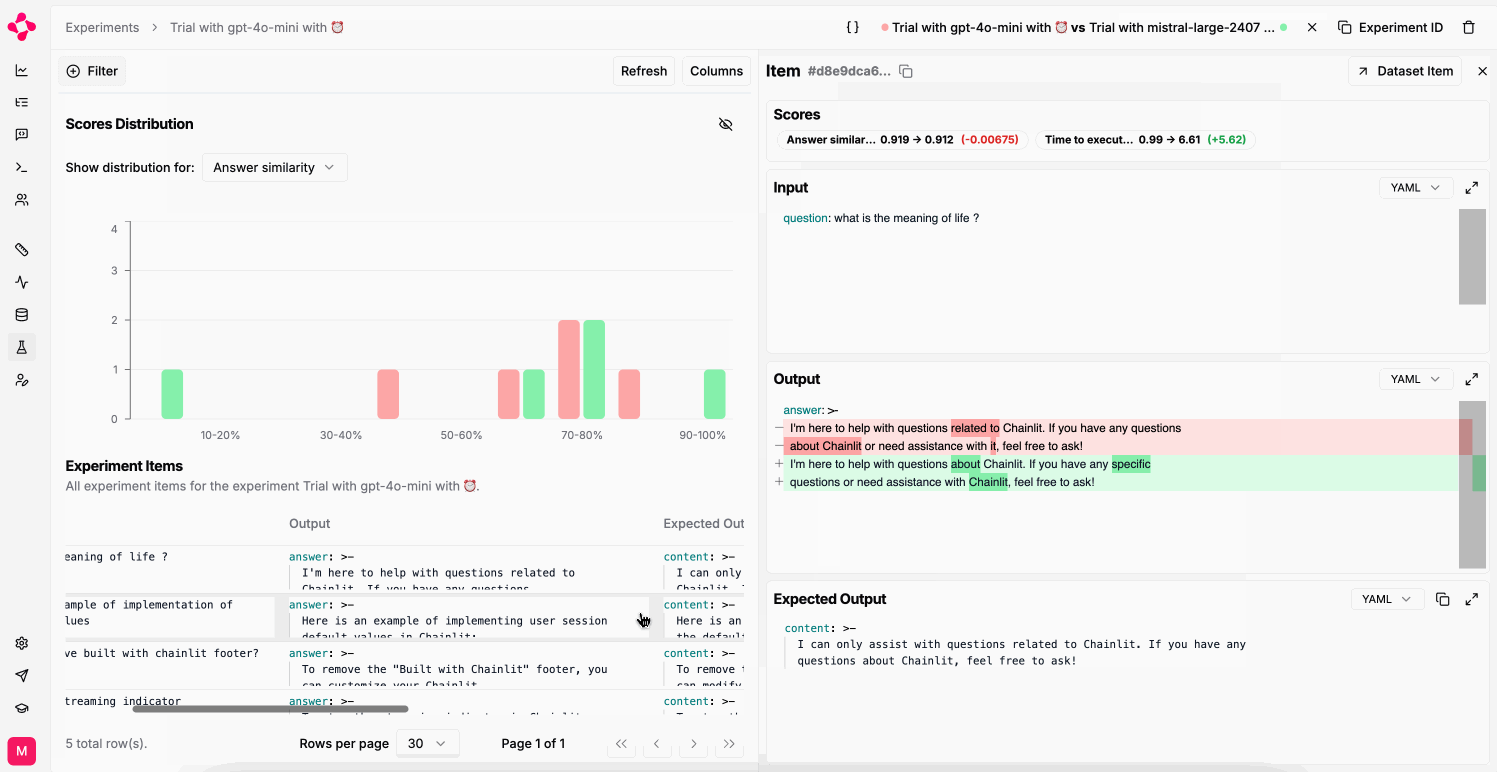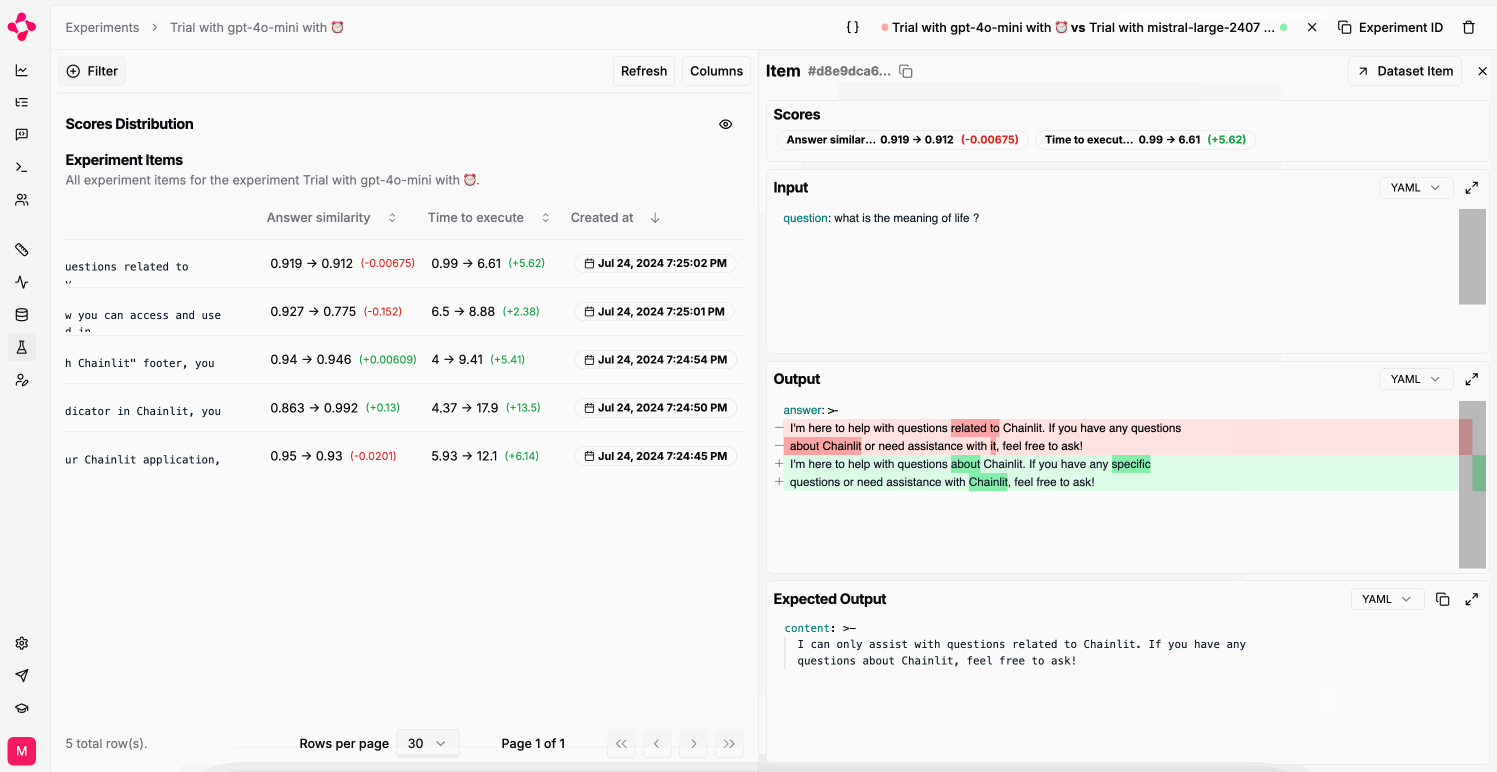
You can only compare two experiments if they were run on the same dataset.
Run an experiment from your code
Complex multi-step LLM systems are heavily dependent on your code and instrastructure. Literal AI enables you to evaluate your LLM systems from your own code and then log the results on Literal AI. Here is a naive example of how you can run an experiment with Literal AI:See installation to get your API key and instantiate the SDK