Semantics

Log Hierarchy on Literal AI
- Generation: Log of a single LLM call. (Generations are Steps.)
- Step: Log of a regular function execution, which is usually an intermediate step in an LLM system. Possible
types are:tool,embedding,retrieval,rerank,undefined, etc. Steps can be considered as Spans. - Run: Trace of an Agent/Chain run, including its intermediate steps. Can contain one or multiple generations.
- Thread: A collection of Runs that are part of a single conversation.
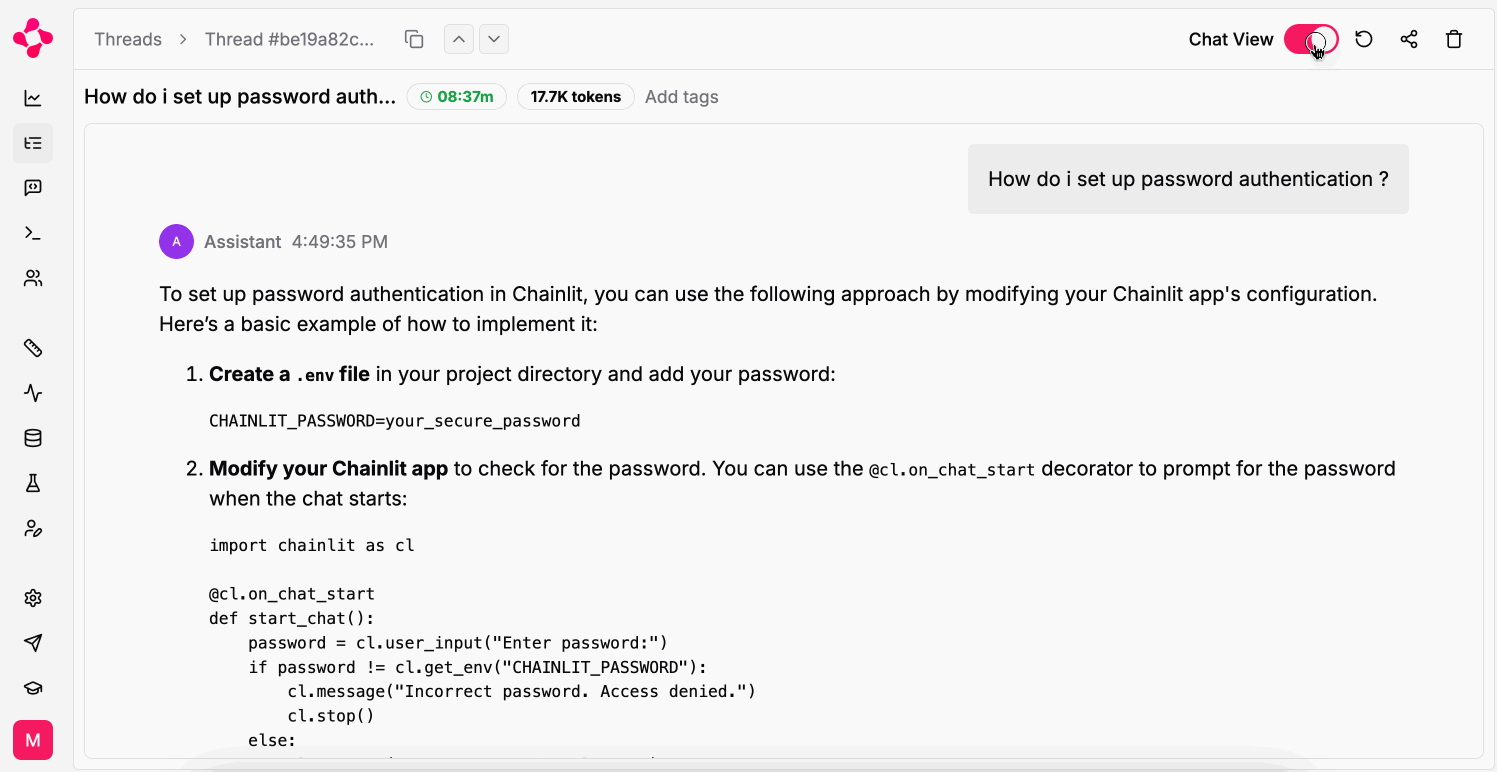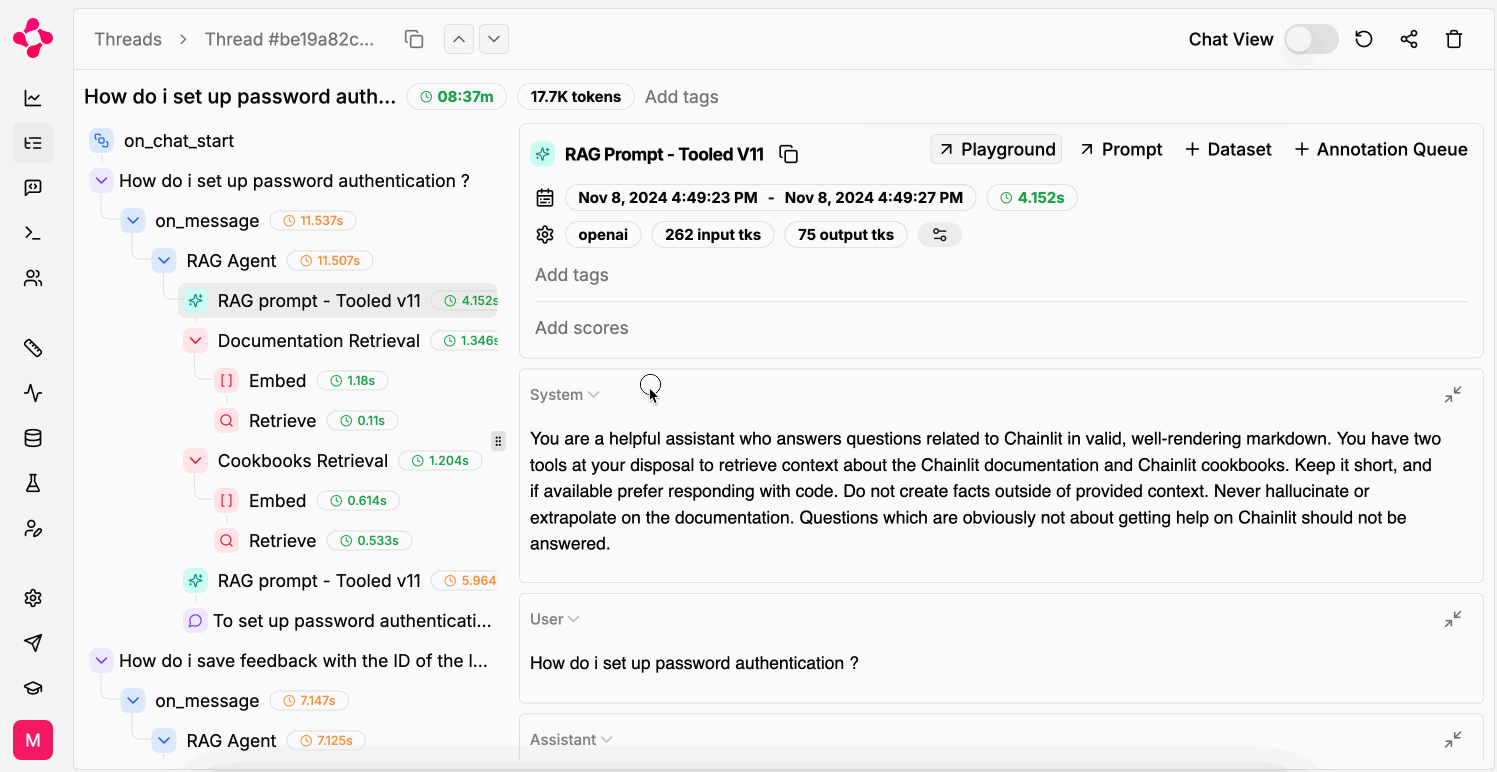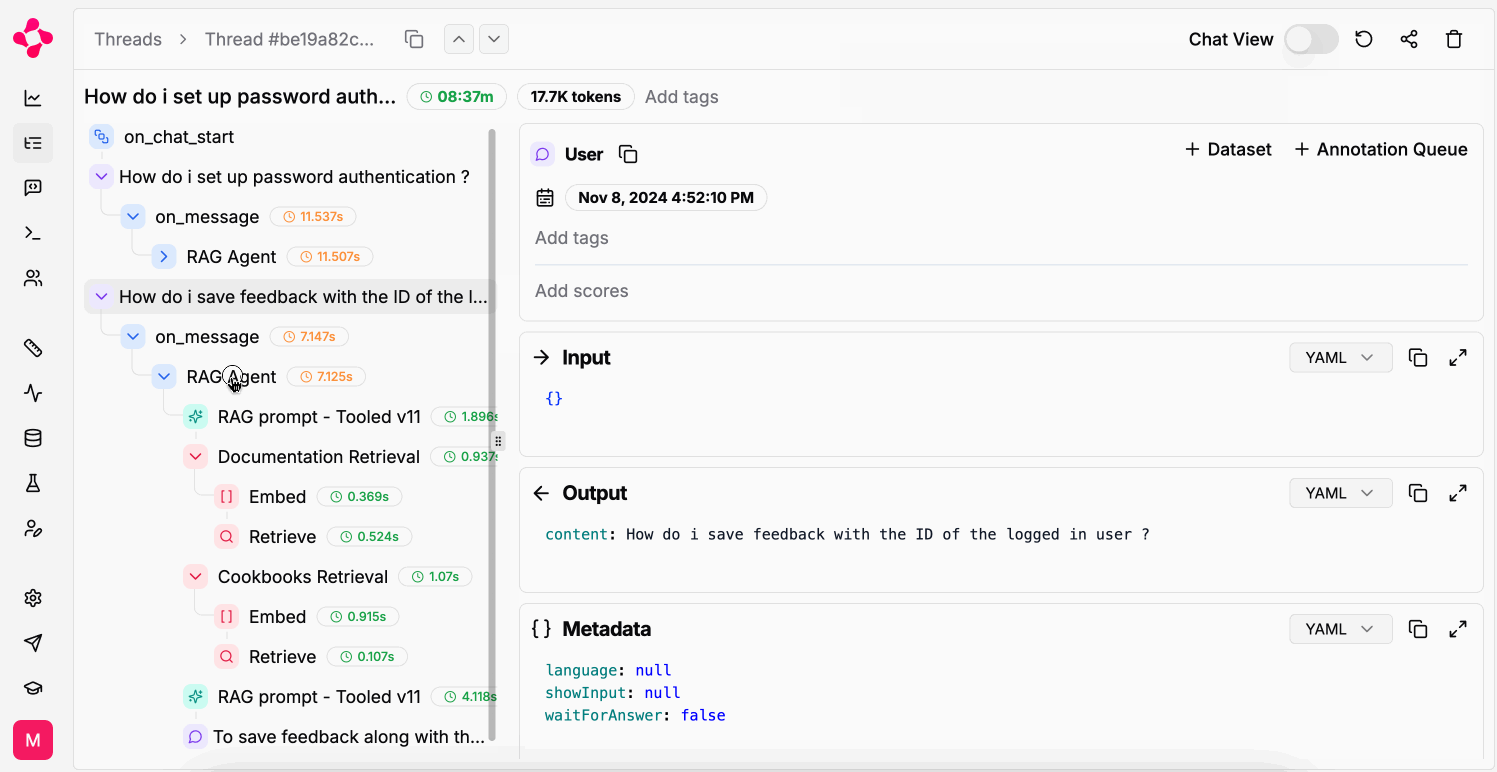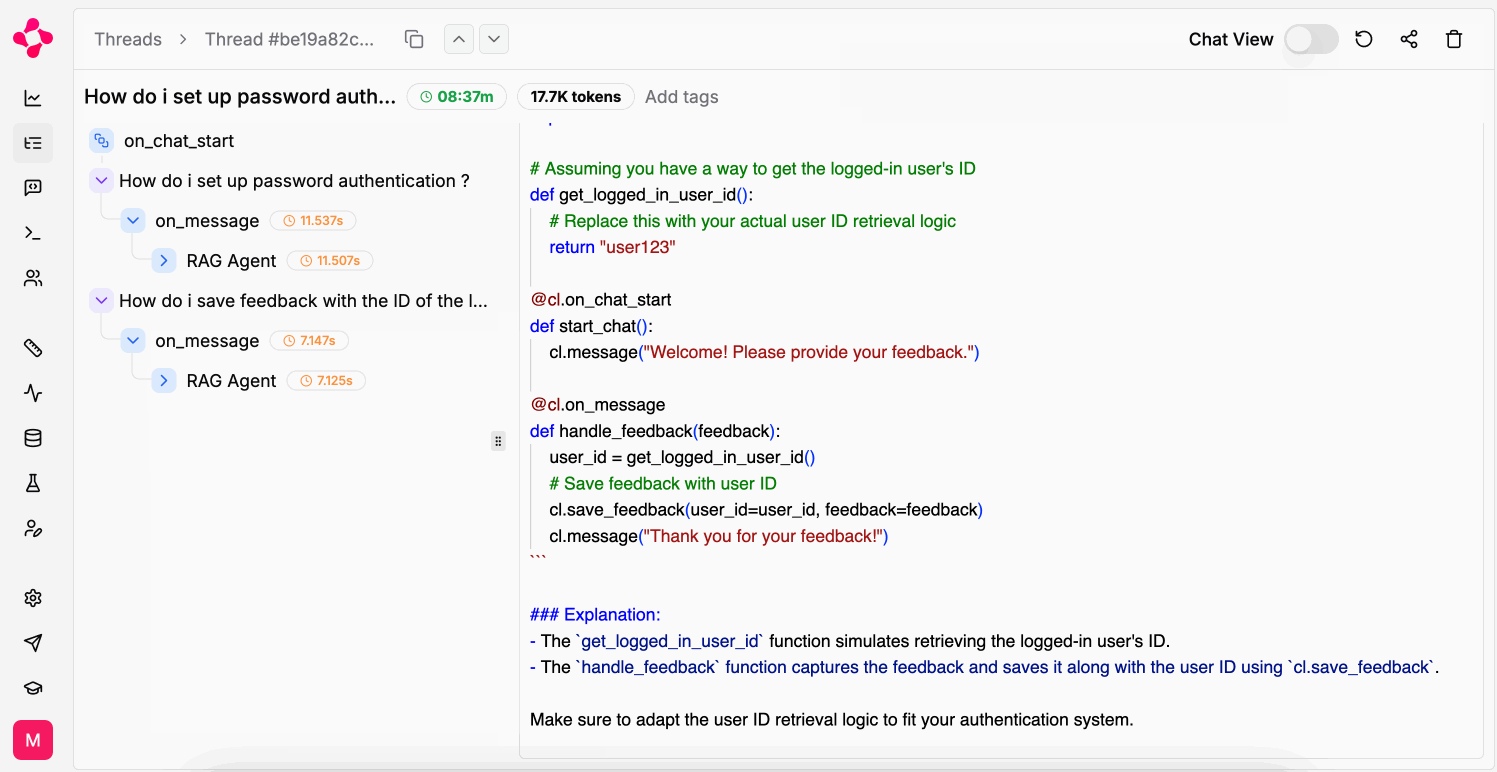
A Thread with runs & intermediate steps
See installation to get your API key and instantiate the SDK
Log an LLM Generation
Generations are logged by integrations with LLM providers. They capture the prompt, completion, settings, and token latency. Here is an example with OpenAI:wrap function.
Multimodal LLM
You can leverage multimodal capabilities on Literal AI in two ways:- Simple logging on API calls to Multimodal LLM APIs, like
gpt-4o - Save multimodal files as Attachments. Image, videos, audio and other files are shown as
Attachmentin the Literal AI platform, which can be accessed and downloaded via aStep.
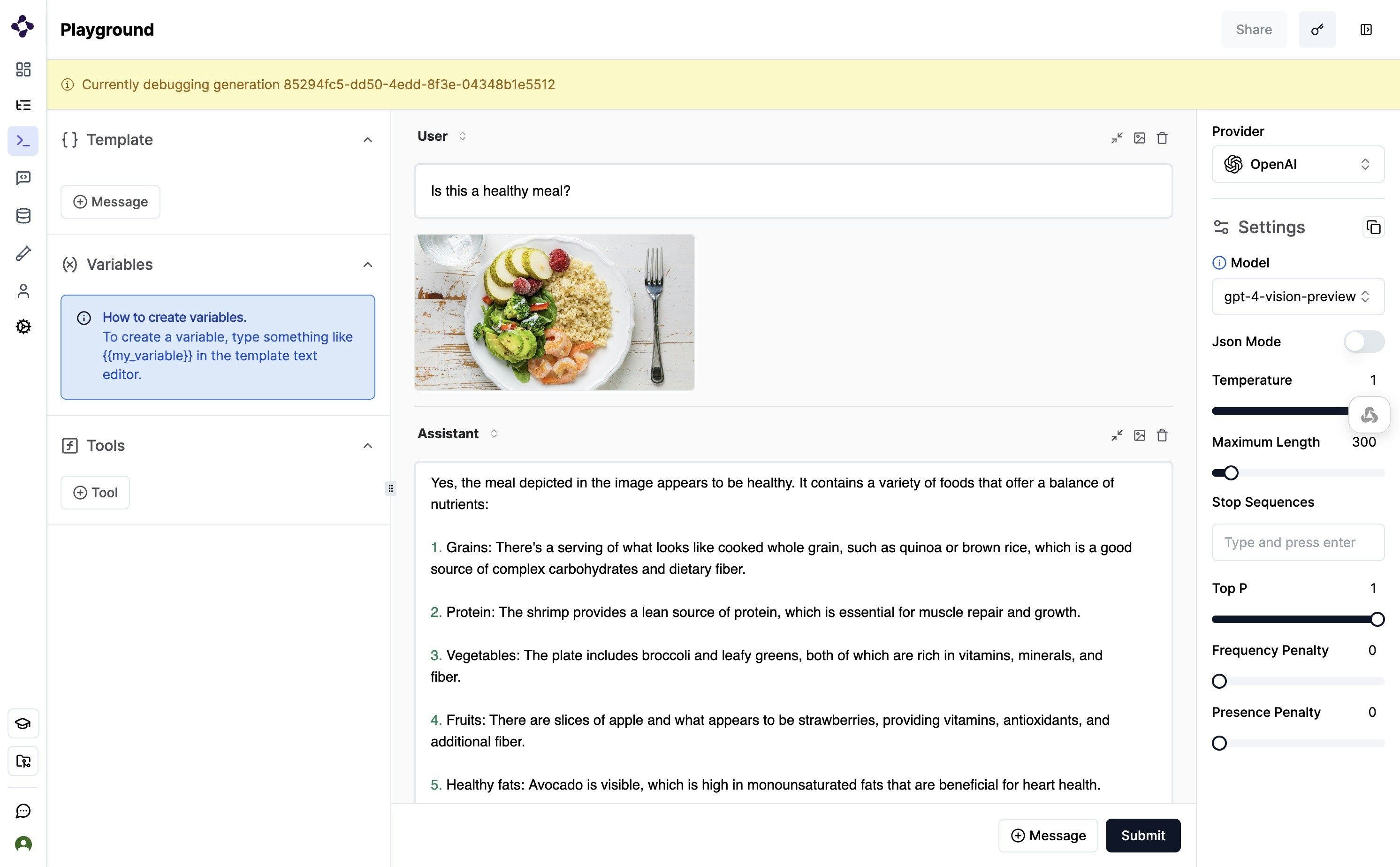
Example of a logged multimodal LLM call
Log a Run
A Run represents a trace of an Agent or Chain execution, capturing all intermediate steps and actions. Runs can be logged manually using decorators or through framework integrations such as Llama Index or LangChain.Log a Run with Intermediate Steps
Here’s how you can log a Run with intermediate steps using Python and TypeScript:Add Metadata and Tags to Steps
Tags and Metadata can be added to both Runs and Steps to provide additional context and facilitate filtering and categorization.Add Attachments to Steps
You can attach files to a Run or any of its intermediate steps, which is particularly useful for multimodal use cases.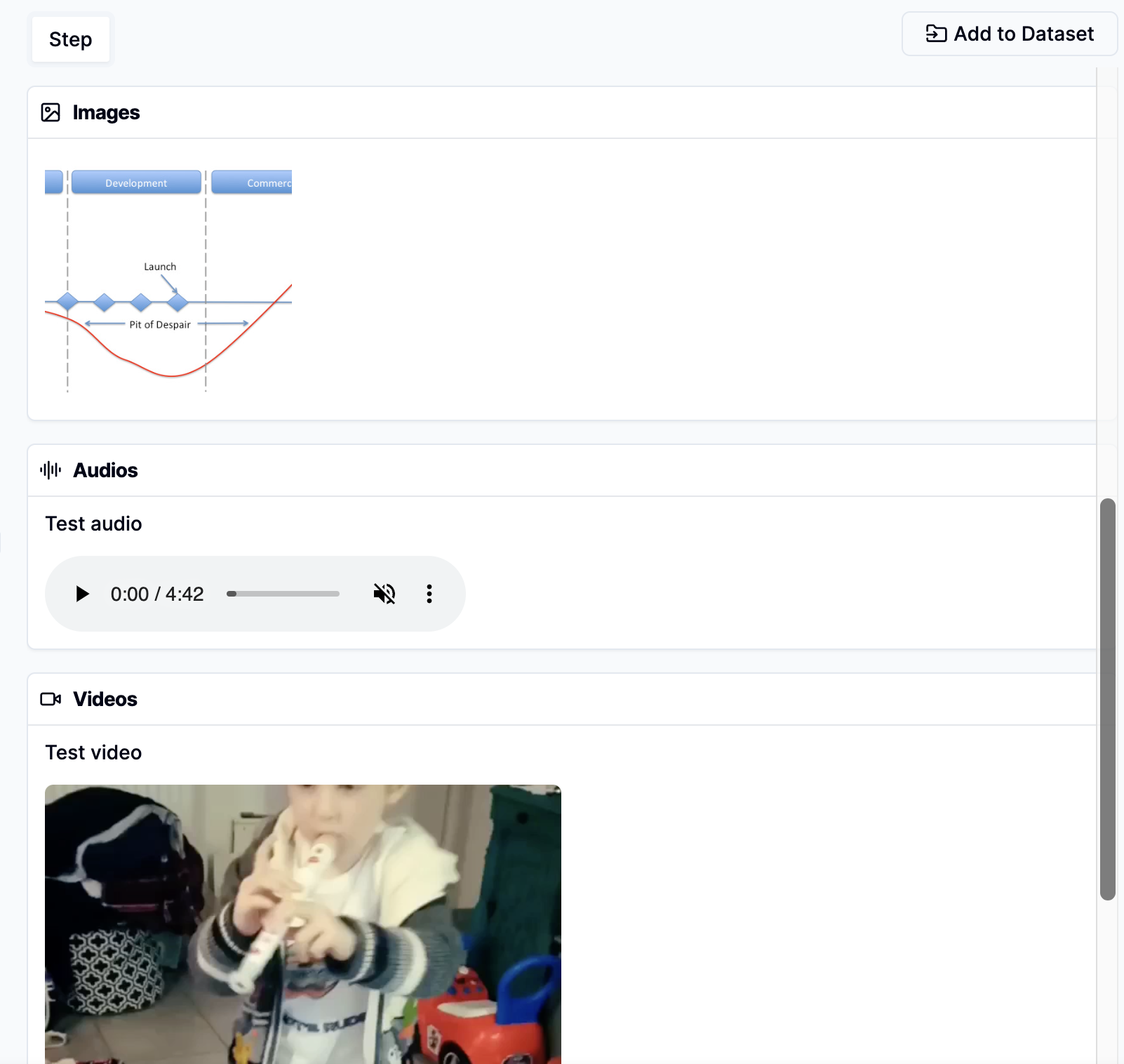
Example of attachments
Learn More
The intermediate steps and the agent itself are logged using theStep class. You can learn more about the Step API in the following references:
Python Step API reference
Learn how to use the Python Step API.
TypeScript Step API reference
Learn how to use the TypeScript Step API.
Log a Thread
You can interact with an example Thread in the platform here. It is up to the application to keep track of the thread ID and pass it to the Literal AI client. Every run logged with the same thread ID will be part of the same conversation. Here is an example:Python Thread API reference
Learn how to use the Python Thread API.
TypeScript Thread API reference
Learn how to use the TypeScript Thread API.
Bind a Thread to a User
You can bind a Thread to a User to track their activity: quite handy for chatbots and conversational AIs!
Simply provide a unique User identifier, such as an email.
You can create a
If your
User at any time with the create_user API.If your
User already exists, you may update its metadata with the update_user API.The Literal AI client method thread() takes a participant_id (participantId in TypeScript) argument which accepts any of:User.id: the unique ID of yourUser— it’s a UUIDUser.identifier: the unique identifier of yourUser— it can be an email, a username, etc.
identifier!Log to a Specific Environment
Literal AI supports logging to different environments, which allows you to separate your development, staging, and production data:dev, staging, prod.
This is particularly useful for managing your LLM application lifecycle.
To specify an environment when initializing the LiteralClient, you can use the environment parameter:
Log with a Release
Literal AI supports pairing your logs to a release, a release is a version of your deployed code to help you identify new issues and regressions. This is particularly useful for managing your LLM application once in production. The value can be arbitrary, but we recommend Semantic Versioning, Calendar Versioning, or the Git commit SHA. To specify a release when initializing the LiteralClient, you can use therelease parameter:
release in the metadata.
Log a Distributed Trace
Distributed Tracing Cookbook
Learn how to log distributed traces with Literal AI.
Add a Score
Scores allow you to evaluate the LLM system performance at three levels: LLM generations, Agent Runs and Conversation Threads.
Add a User Feedback
Add a Product-Related Metric
Correlate your LLM system to a product metric, such as conversion, churn, upsell, etc. This can be done by:- Adding a specific product-related score on Literal AI.
- Sending the logged run id to your analytics system, such as PostHog or Amplitude.
Add an AI Evaluation Result
Refer to Online EvalsFetch Existing Logs
You can fetch existing logs using the SDKs. Here is an example to fetch the last 5 threads where a user participated:On Literal AI
Filter logs
Leverage the powerful filters on Literal AI. Use these same filters to export your data using the SDKs.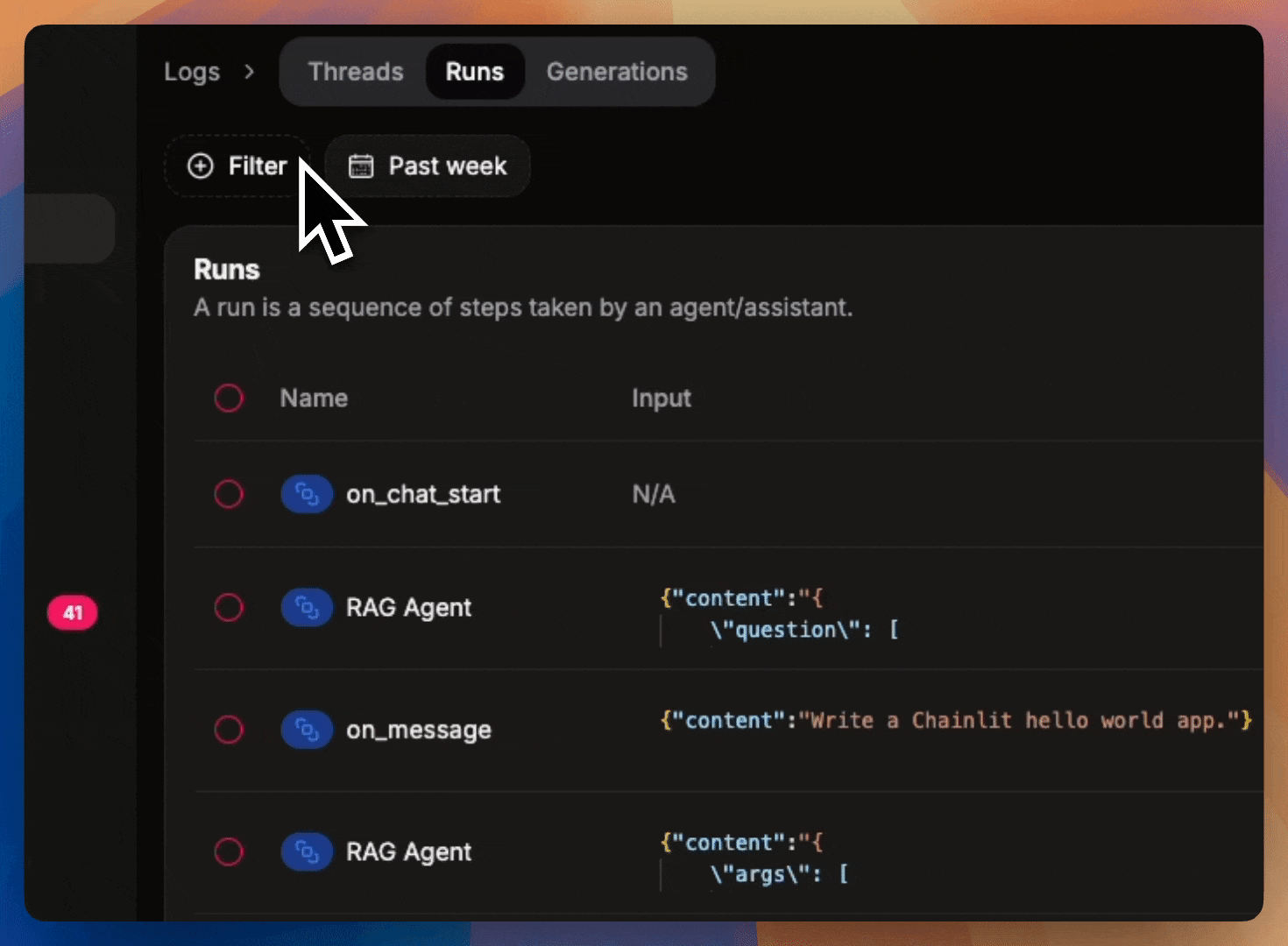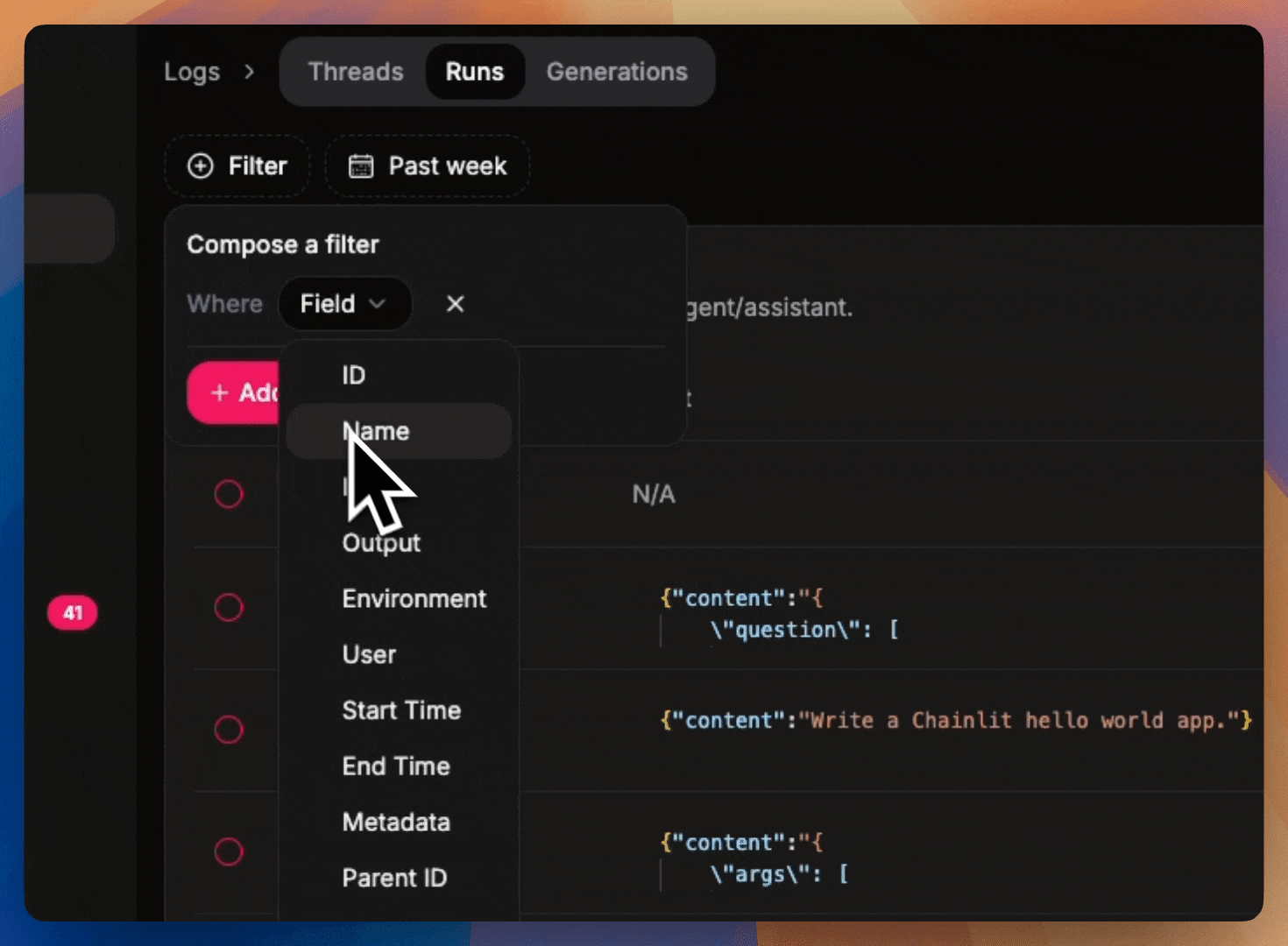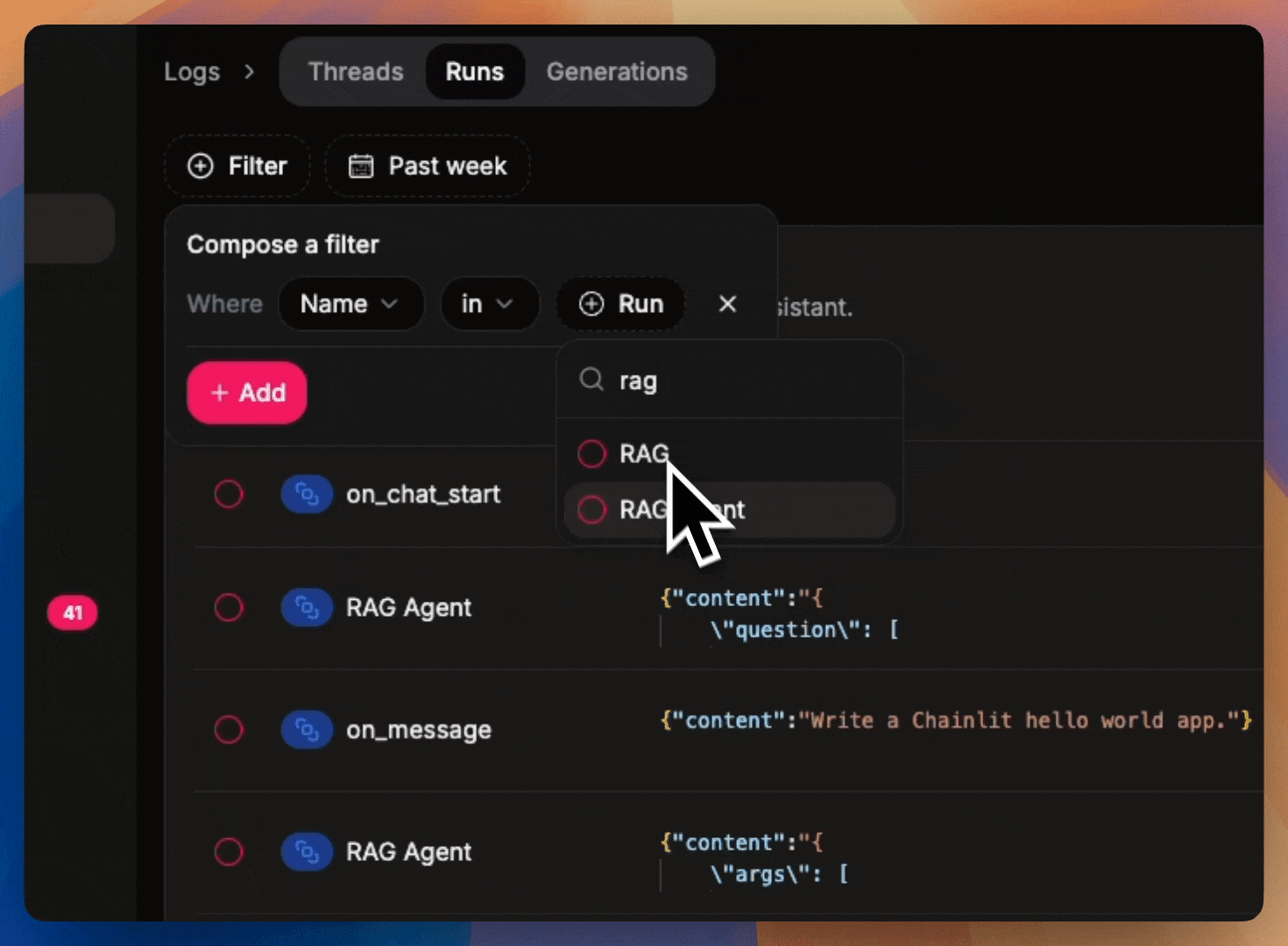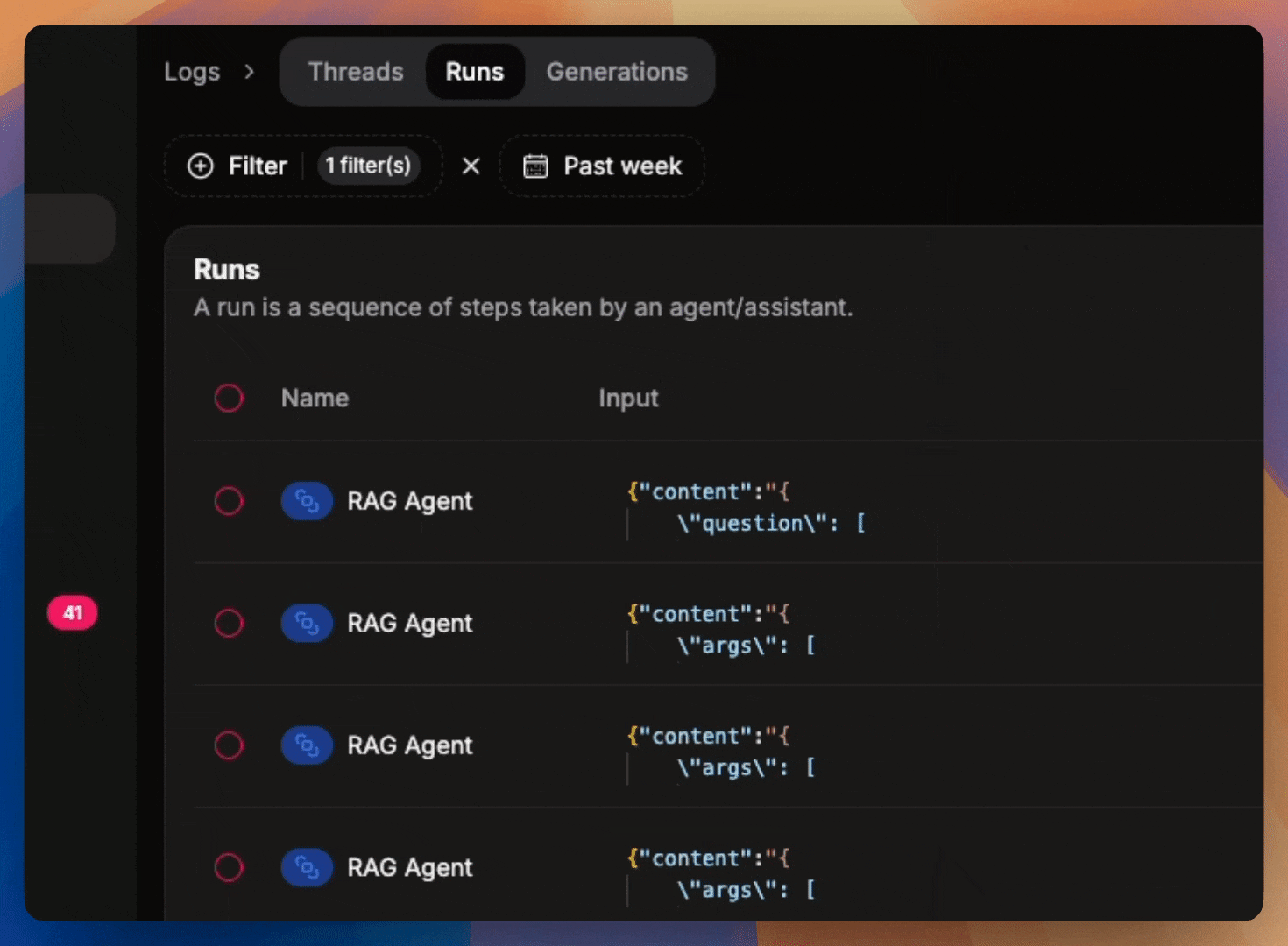
Filter on logs
Debug logged LLM generations
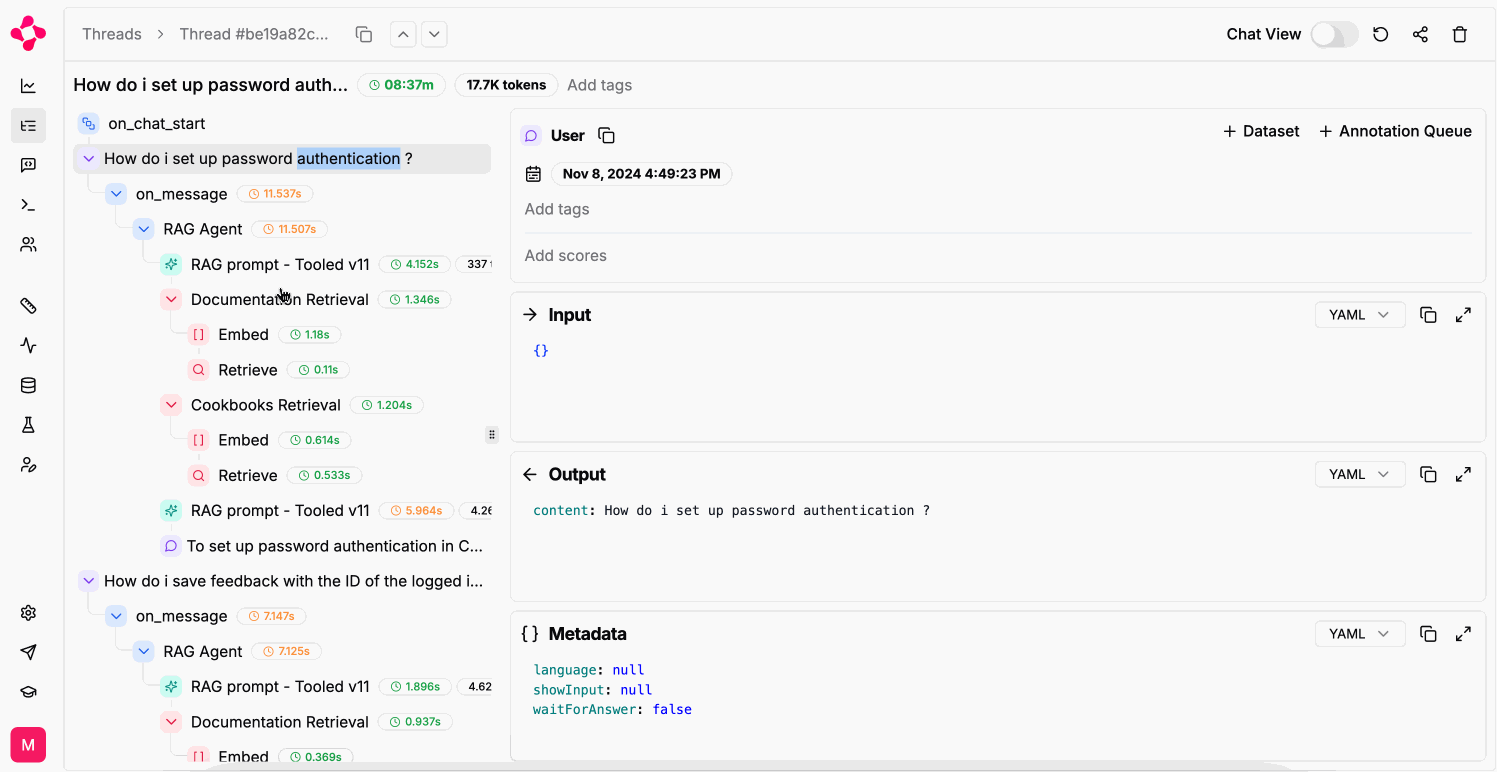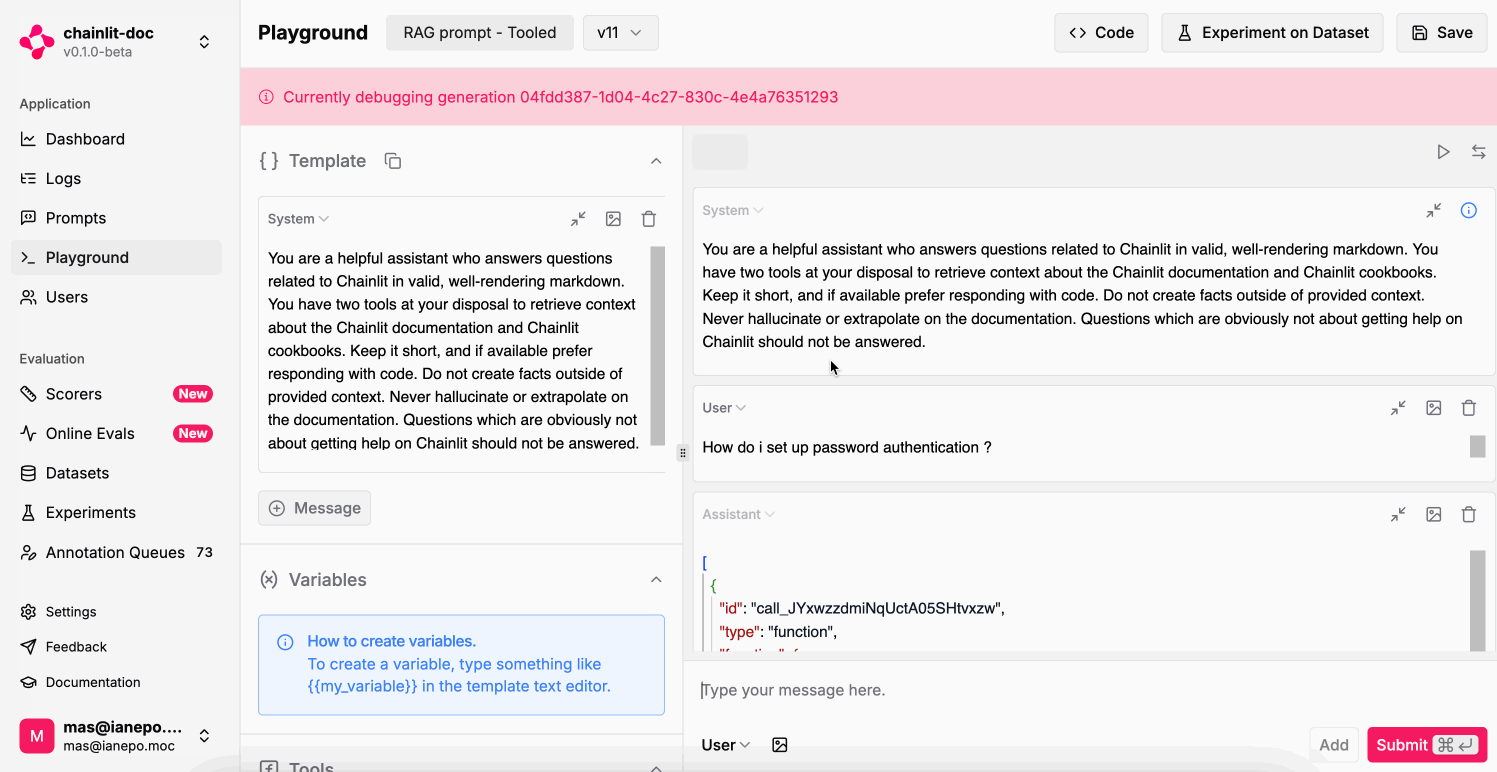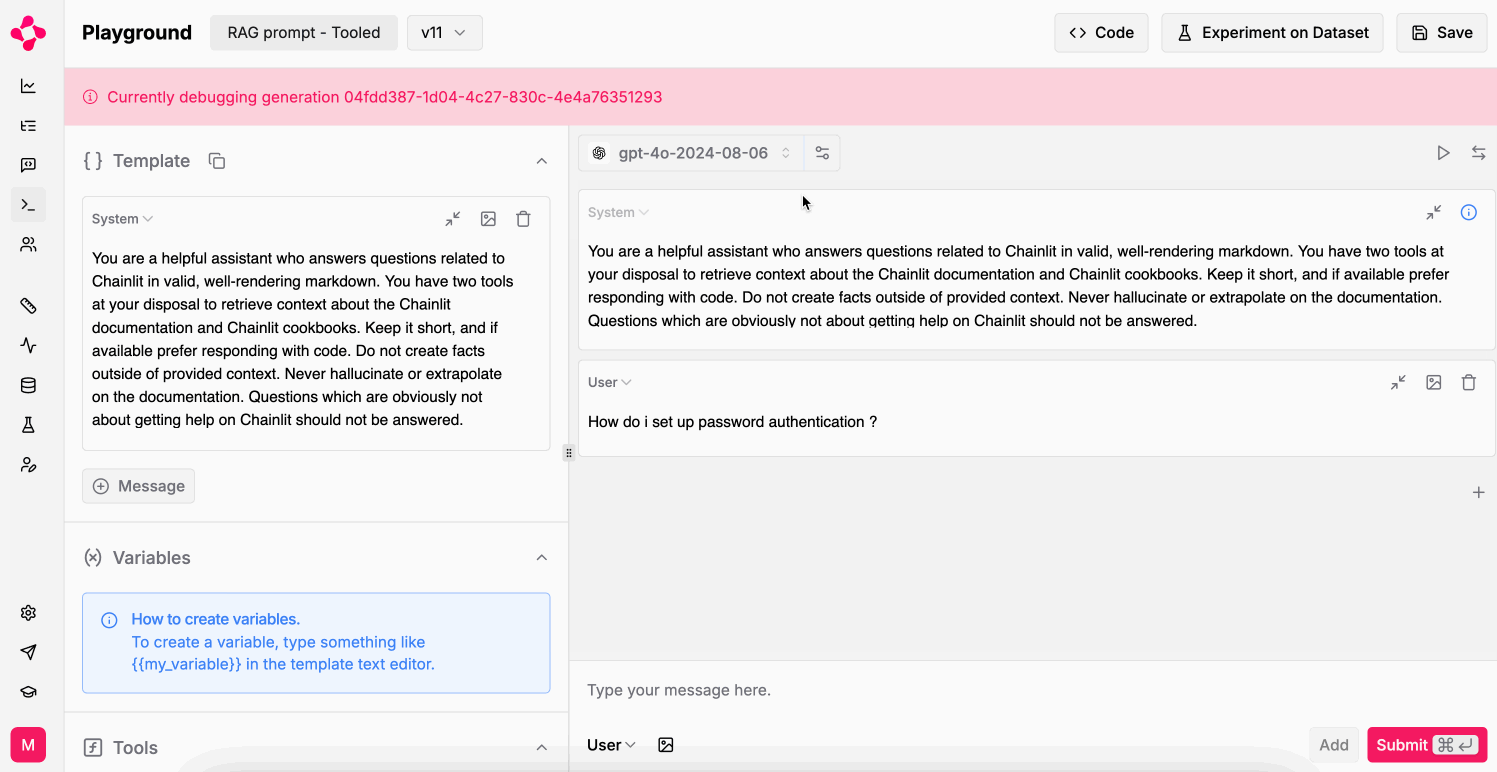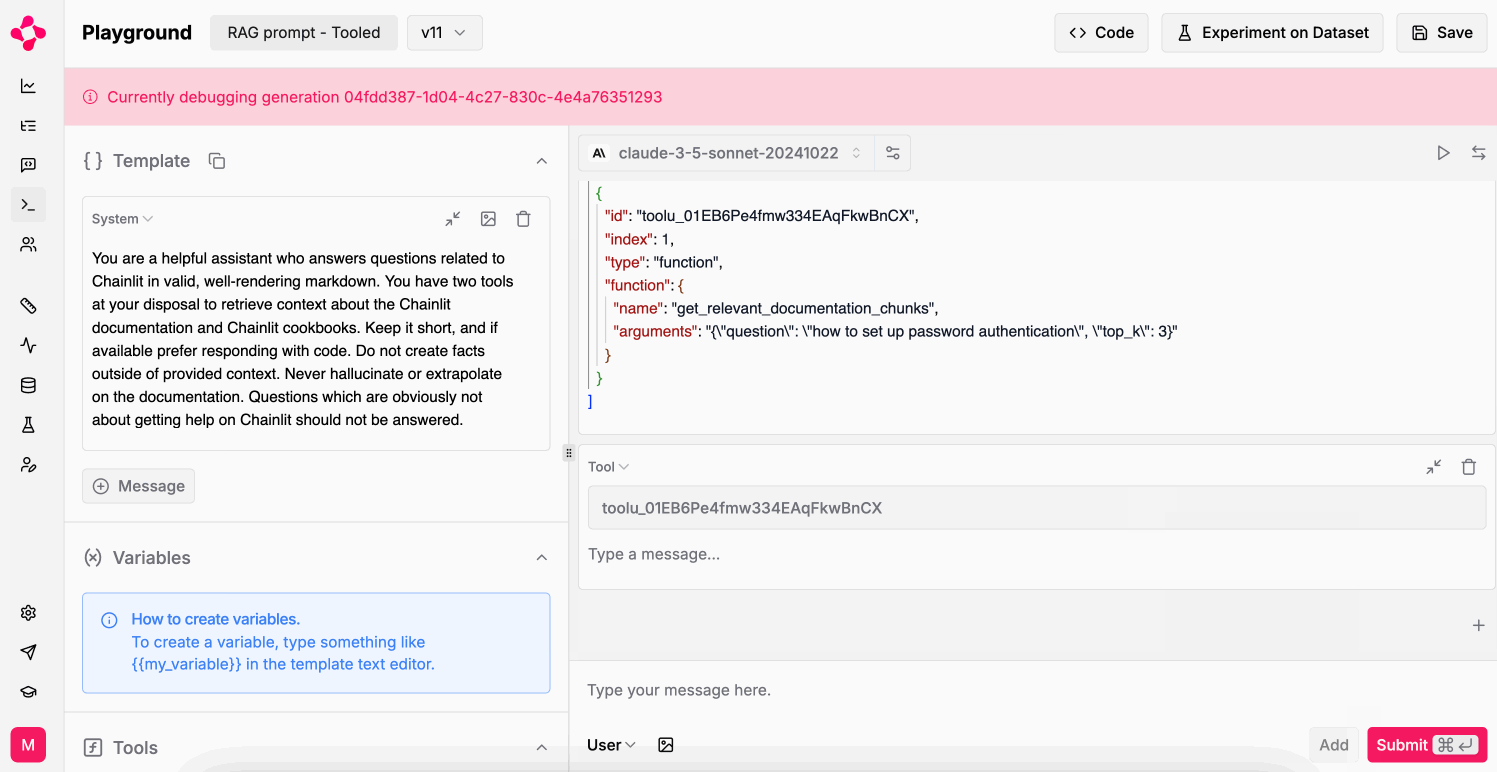
Replay a logged LLM generation in the Playground
Add Tags and Scores from the UI
You can add tags and scores directly from the user interface.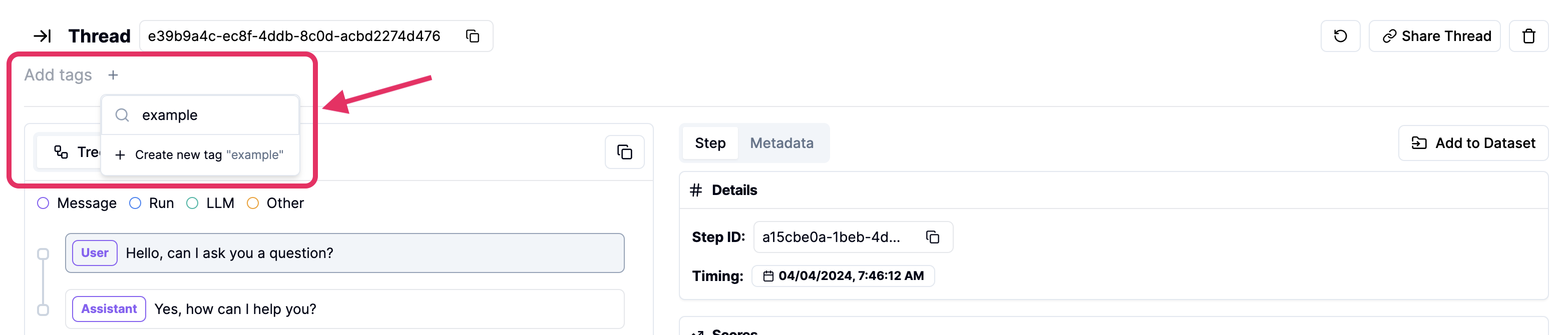
Add a Tag to a Thread