From the Literal AI Platform
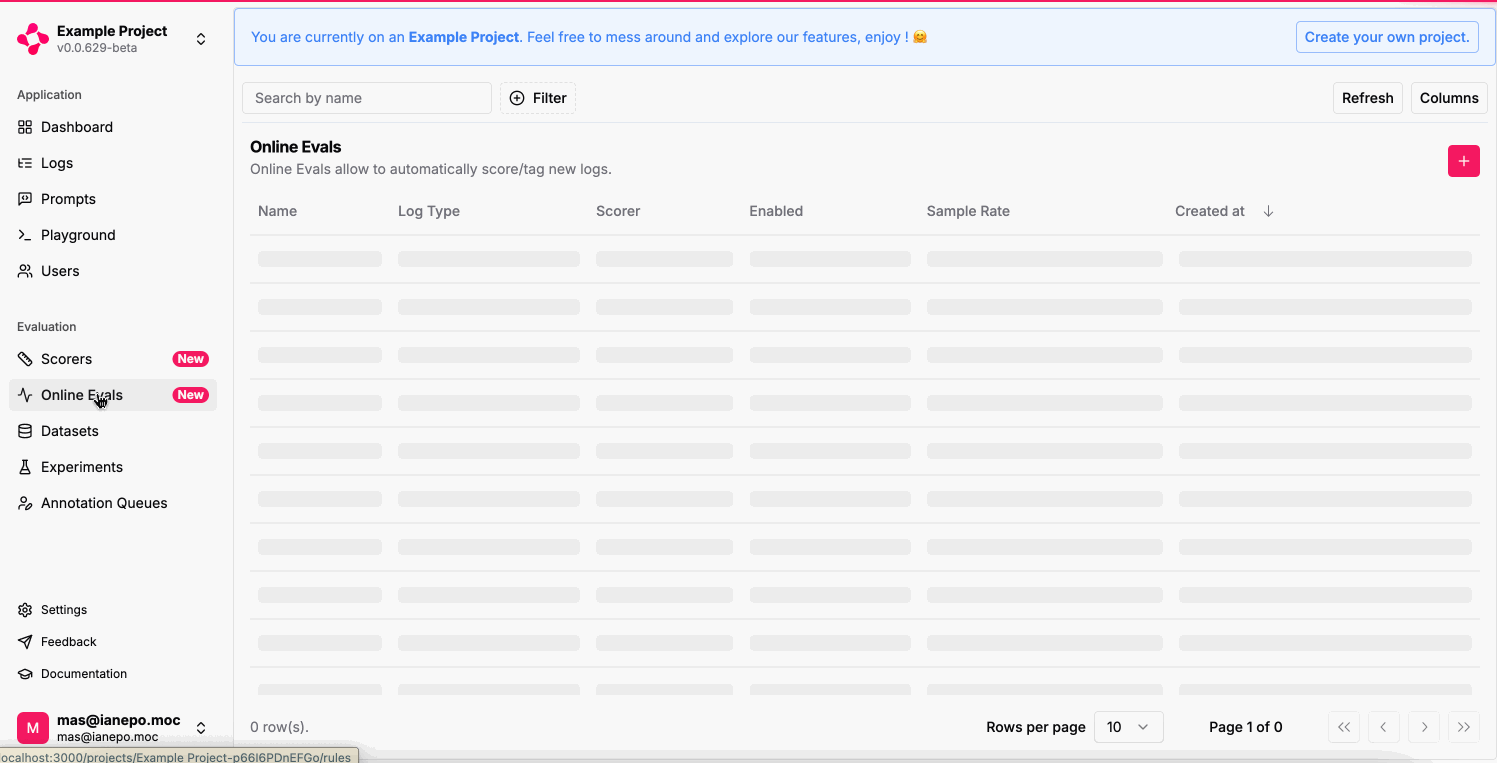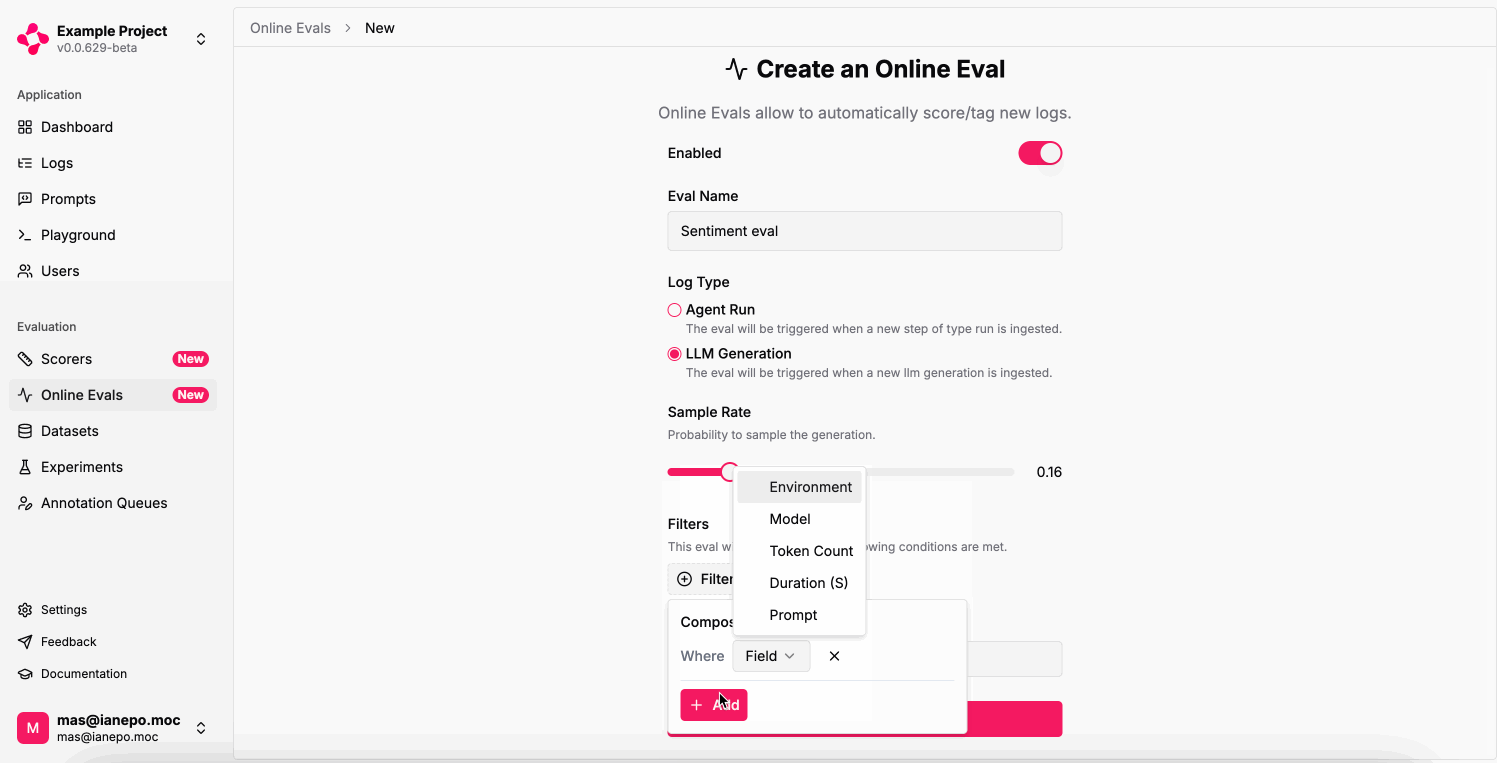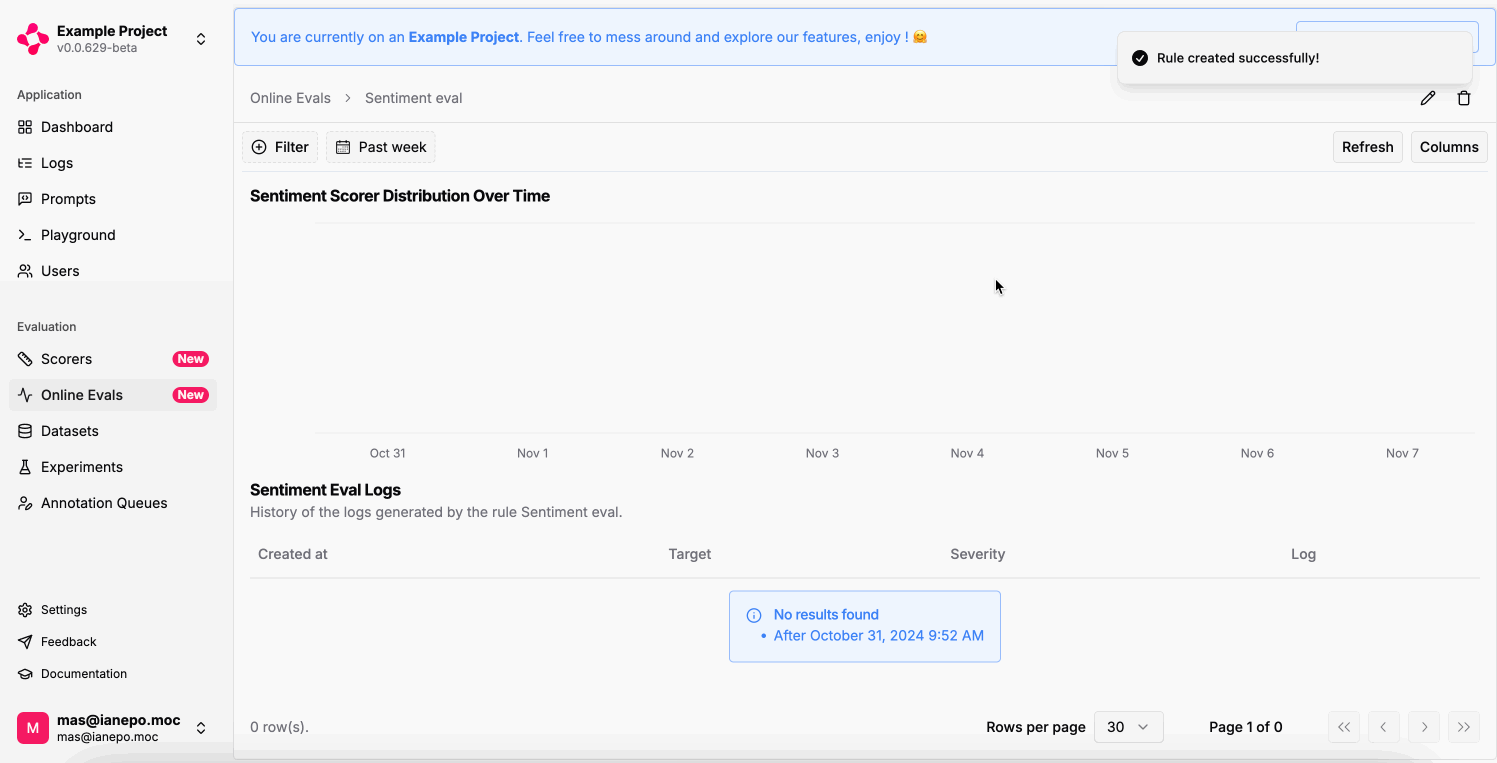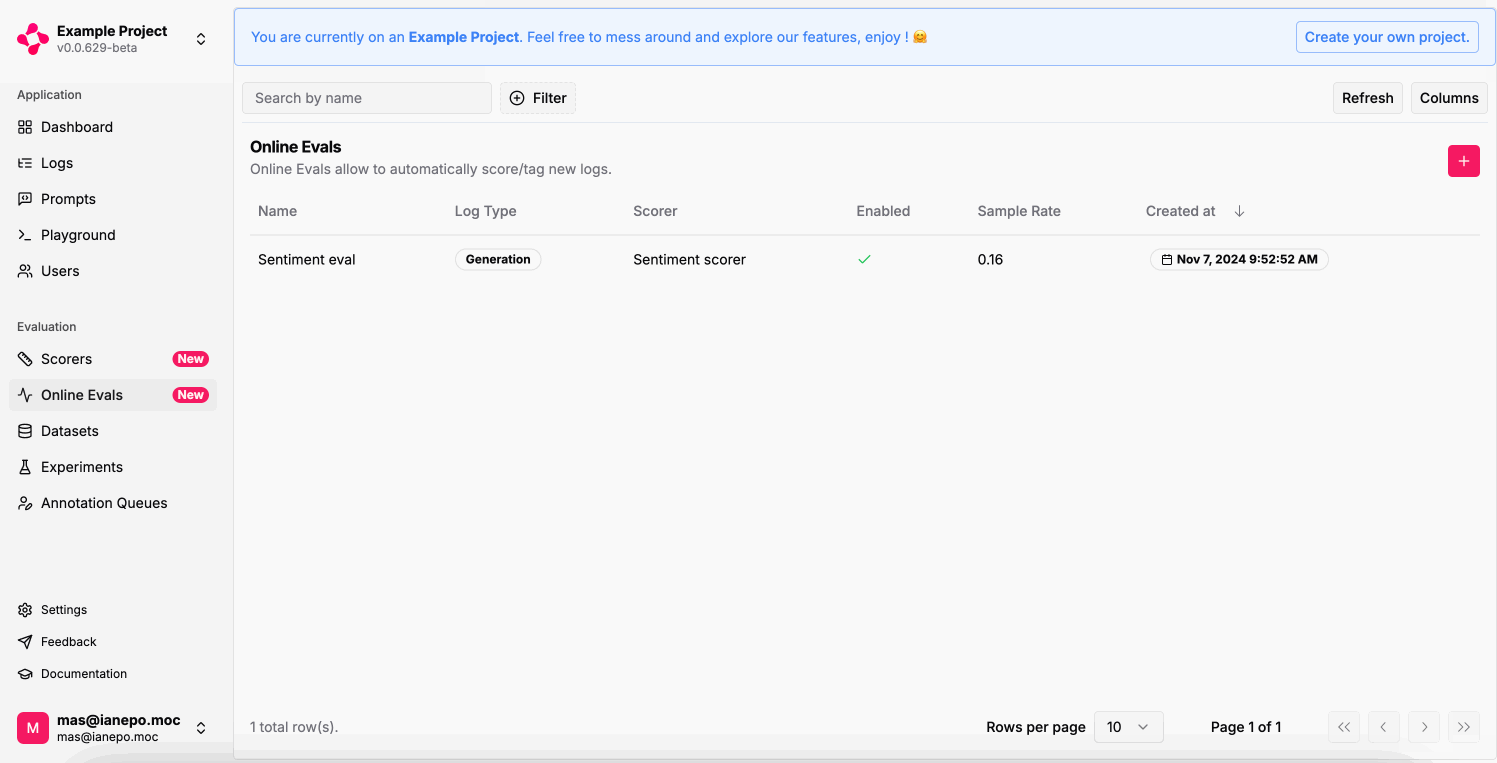
Automating the evaluation of your Run outputs or LLM generations can significantly help detect patterns and areas of improvement for your LLM app in production, especially with large volumes of data. An Online Eval is composed of:- Name: A name to identify the rule.
- Log Type: Either
Agent RunorLLM Generation, it’s the target to evaluate. - Sample Rate: The percentage of logs to evaluate.
- Filters: Additional conditions to selectively evaluate certain logs.
- Scorer: The scorer to use for the evaluation.
Online Evals page and click on the + button in the upper right corner of the table.
Create Online Eval
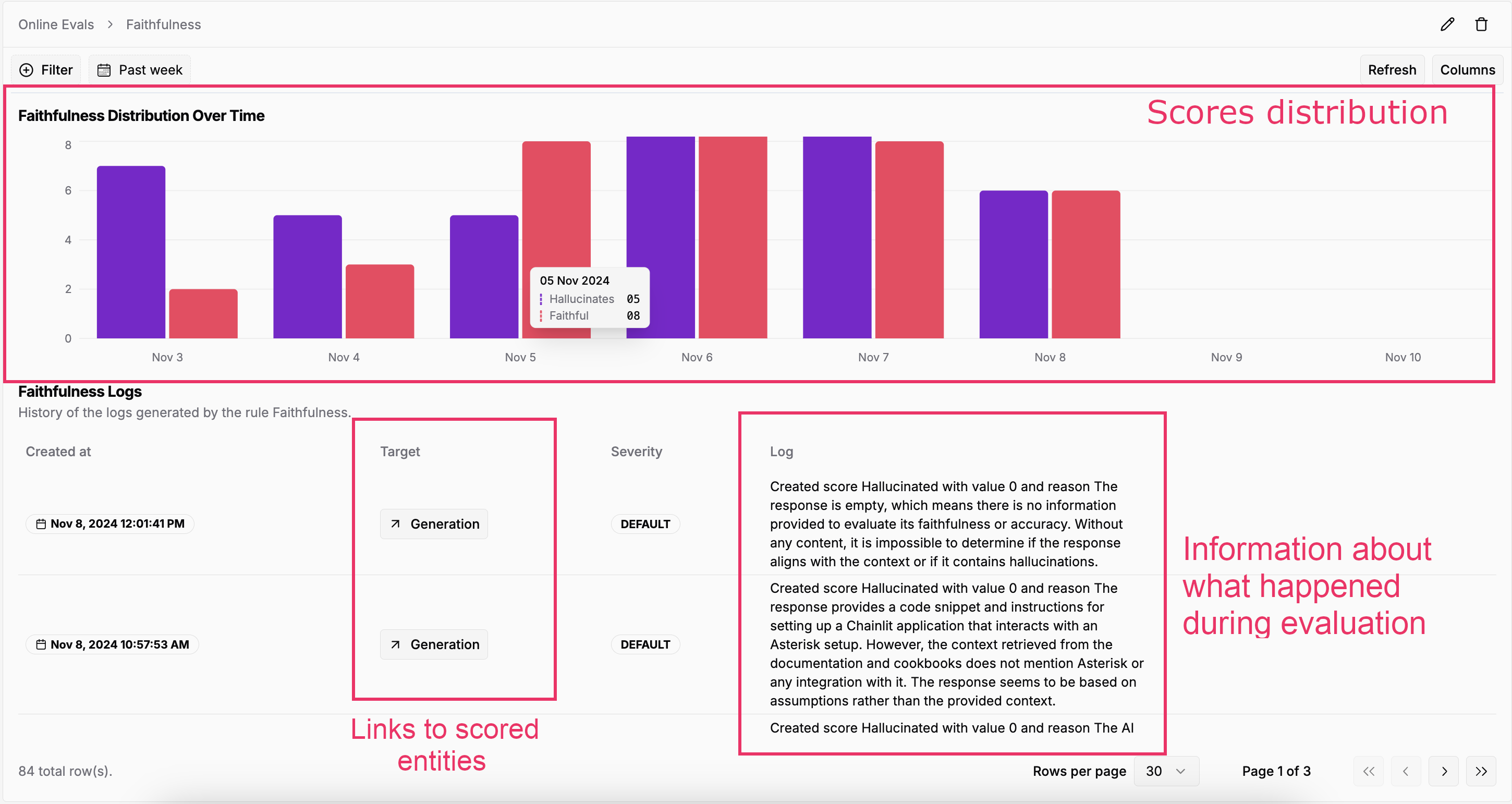
Online Eval Scores Distribution
If an Online Eval failed on a Run or LLM Generation, the
Log column will show the error message.From the SDKs
The SDKs provideScore creation APIs with all fields exposed.
If your metrics are code-based or combine LLM calls with arithmetic operations, like Ragas, you can
directly use the SDKs to create scores from your application code.
Scores must be tied either to a
The concept of
Step or a Generation object.The concept of
Score on a Thread is not well-defined at this stage.Automation of actions based on evaluation results is coming soon!