> ## Documentation Index
> Fetch the complete documentation index at: https://docs.literalai.com/llms.txt
> Use this file to discover all available pages before exploring further.
# Fine-tuning
> Fine-tune your LLM models to improve performance and reduce costs.
Fine-tuning is the process of training an existing Machine Learning model -- LLM here -- on a custom dataset of input/output examples.
## How it works
### Fine-tuning
LLM providers offer fine-tuning as a service, you simply need to provide the trainign data in the right format.
Behind the scenes, the LLM provider freezes the original model's weights and slides in a few layers of trainable weights (LoRA).
Training happens on the LLM provider's infrastructure and the loss function (cross-entropy) is the metric optimized against.
Best practices are to pass in a training and a validation dataset to ensure your fine-tuned model is not overfitting.
Do not forget to test your final model beyond the next-token prediction task: you should set benchmarks to evaluate the performance of the
fine-tuned model on the real-world task you plan to use it on: summary, extraction, tone of voice, RAG, etc.
### Dataset export
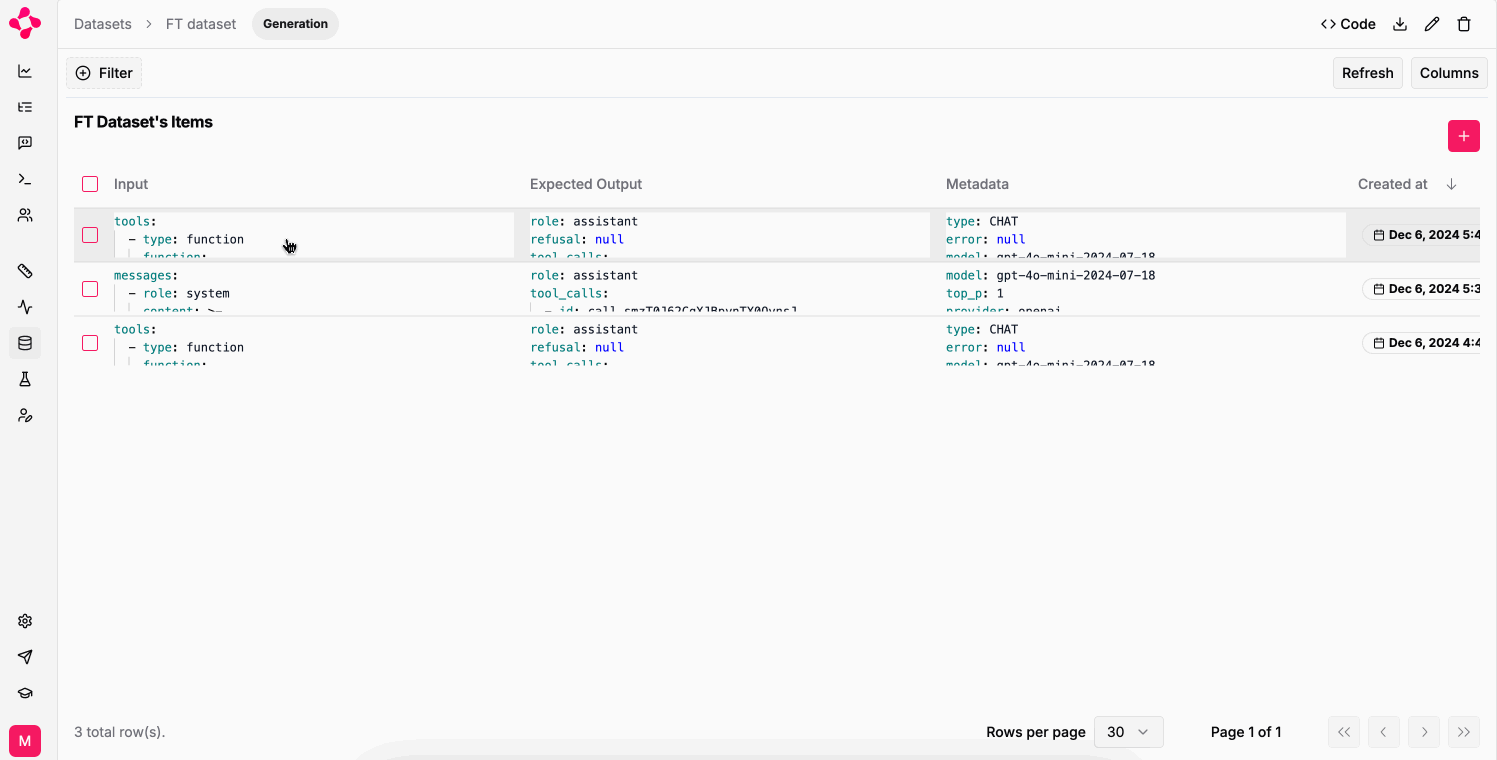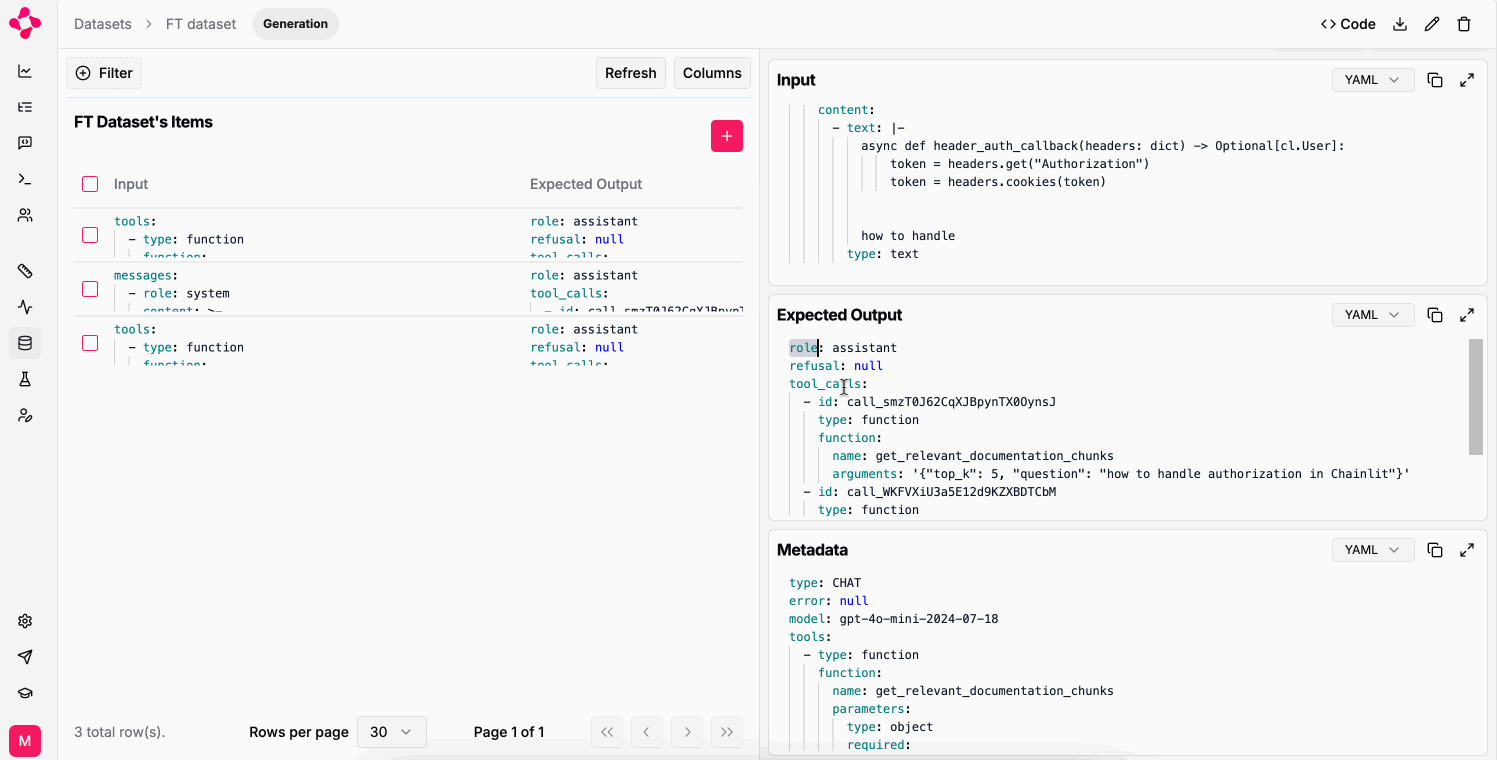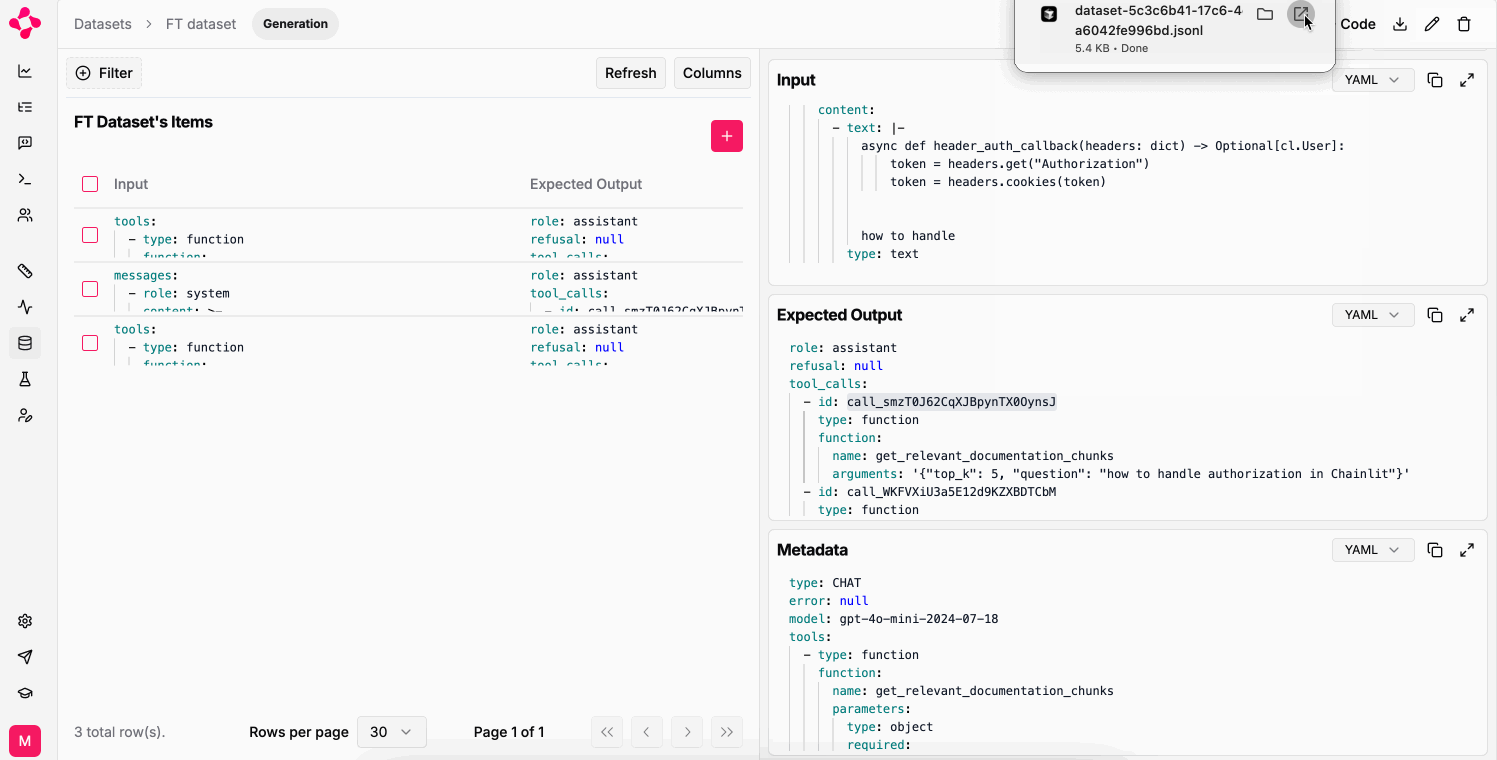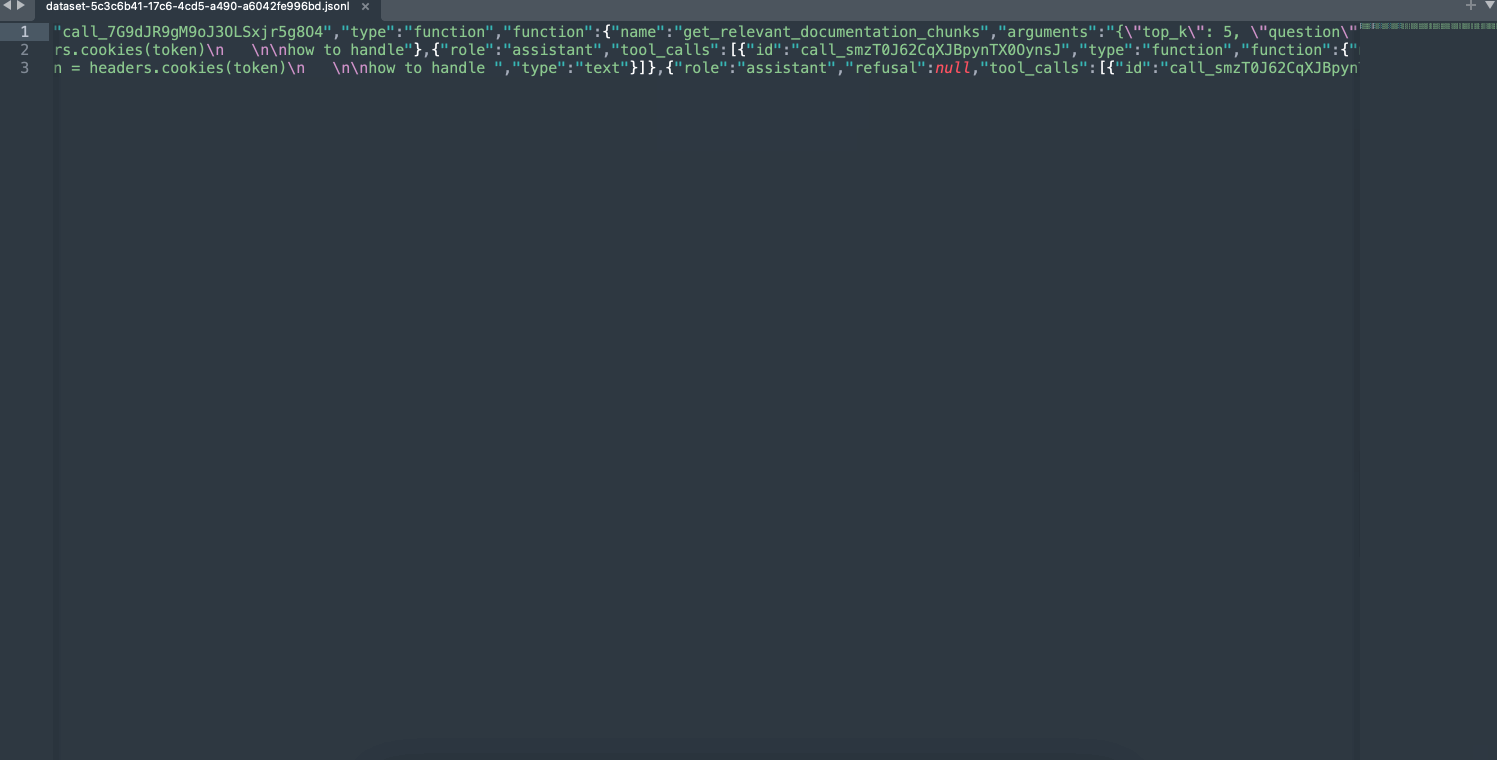
Literal AI simplifies the creation of training datasets with `Generation` datasets.
You can build `Generation` datasets from your logs, or from your annotation queues: the format is compatible with the OpenAI fine-tuning format.
To download your datasets as JSONL (JSON Lines) files, you can use the `Download` button on the dataset page:
 ## Distillation
Often-times, the hard part is to come up with the right dataset to train on. It should be:
* high quality
* representative of the real-world task you want to use the model on
* large enough to train a good model
From production logs generated with a high-performance LLM, you can automatically generate mulitple quality samples of input/output messages.
Once you have built a stable enough dataset, you can reduce costs by fine-tuning a smaller model on the data you gathered.
This is what is called **distillation**: you are distilling the knowledge of the original model into a smaller model.
## Distillation
Often-times, the hard part is to come up with the right dataset to train on. It should be:
* high quality
* representative of the real-world task you want to use the model on
* large enough to train a good model
From production logs generated with a high-performance LLM, you can automatically generate mulitple quality samples of input/output messages.
Once you have built a stable enough dataset, you can reduce costs by fine-tuning a smaller model on the data you gathered.
This is what is called **distillation**: you are distilling the knowledge of the original model into a smaller model.